







技術分享
 友善列印
友善列印[技術分享]NonStop Server系統效能技術分析(下)
作者/馬先讓
作者簡歷作者擁有26年IT服務資歷,現職凌群電腦NSK服務總處副總工程師,主要負責HPE Nonstop 證券、期貨、銀行客戶交易系統維運服務,專長為HPE NonStop系統整合。
前言
HPE NonStop Server系統效能分析包含了很多面向,上一期文章針對系統效能分析MEASURE工具操作做了說明,本期文章會針對如何快速分析MEASURE DATA的方式做詳細說明。
自動分析MEASURE DATA
一、凌群提供用ENFORM撰寫MEASURE分析REPORT,程式清單如下:
- WCPU:分析CPU BUSY
- WIPU:分析每顆CPU內IPU BUSY
- WDISC:分析DISC BUSY
- WDISCACH:分析DISK CACHE
- WDSCOPEN:分析DISK內檔案的READ/WRITE
- WPROCESS:分析PROCESS BUSY
- ZDFWAIT:分析檔案LOCKWAIT
- WOPENX:分析檔案READ/WRITE 是那些PROCESSES 造成
二、其他相關執行的OBEYFILE如下:
- 執行自動分析報表的程序
- MEASOBY2:將CPU、DISC、PROCESS、DISCOPEN產生成CODE 170的MEASURE DATA FILE,供ENFORM分析。
- MEASOBY4:將CPU用LISTALL CPU *方式產生每個時間點的值到MEASURE DATA FILE,讓ENFORM報表程式-WIPU分析每個時間點CPU/IPU BUSY值。
- ENFOB2:執行ENFORM報表程式。
- MEASSTRT:收集MEASURE OBEYFILE
- MEASSTOP:停止收集MEASURE OBEYFILE
產生的報表可以轉成文字檔透過EXCEL做排序分析。
三、建立自動分析MEASURE環境
- 到一個新的目錄,複製系統$SYSTEM.SYSnn.MEASDDLS到該目錄,執行DDL/IN MEASDDLS/DICT !
- 執行完DDL後就會在該目錄建立MEASURE的DICTIONARY,如下
- 將報表程式放入該目錄內,以及其他分析報表所需的檔案
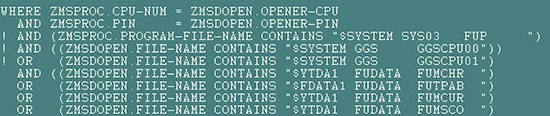
《圖一》
《圖二》
《圖三》
四、收集MEASURE-MEASSTRT/MEASSTOP
- 執行收集MEASURE程序
- 等待收集一段時間後,再執行:RUN MEASSTOP MDATA 即完成收集該時間的MEASURE會產生CODE 175的MDATA檔案
RUN MEASSTRT MDATA
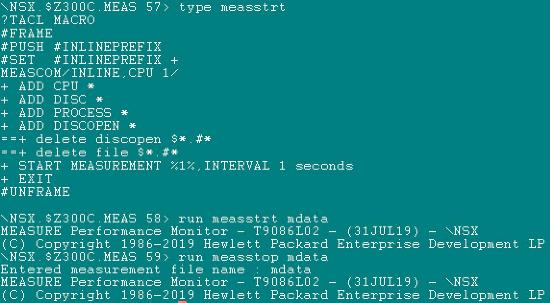
《圖四》
五、執行分析MEASURE REPORT - A
- 執行分析MEASURE OBEYFIL
RUN A MDATA
執行完後,它會將REPORT 檔案放到OUT的目錄內。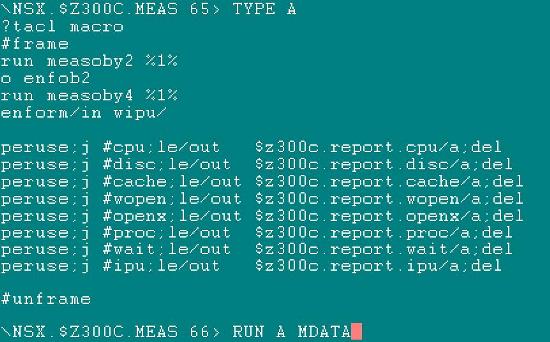
《圖五》
執行完後,它會將REPORT 檔案放到OUT的目錄內。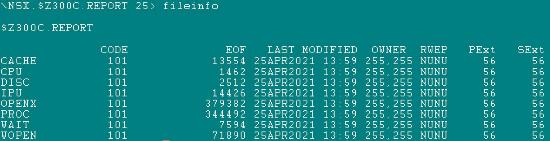
《圖六》
將這些檔案下載至PC查看。
六、分析CPU REPORT- WCPU
- CPU REPORT是分析系統CPU上的負載是否平均
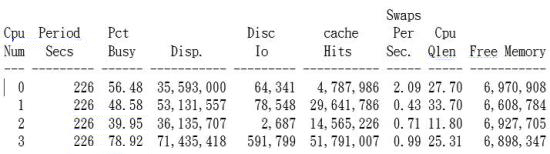
《圖七》
Pct Busy:這段時間內CPU的BUSY %
Swaps:這段時間內CPU的Swaps
Cpu Qlen:這段時間內CPU的Qlen
七、分析DISC REPORT- WDISC
- DISC REPORT是分析系統上的DISK是否有DISK BUSY過高(超過15) 若有的話,要再分析該DISK的WOPEN報表,找出負載過重的檔案。
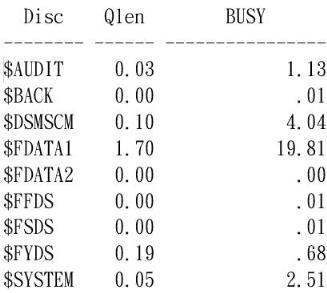
《圖八》
BUSY:該值為DISK的DEVICE-QBUSY-TIME,需低於15%
八、分析CACHE REPORT- WDISCACH
- CACHE REPORT是分析系統上的DISK CACHE是否足夠
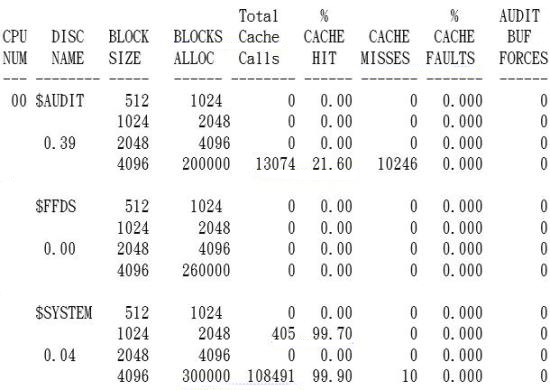
《圖九》
%CACHE HIT:DISC CACHE READ HIT 要大於95%
九、分析PROC REPORT- WPROCESS
- PROC REPORT 是分析系統上的PROCESS BUSY
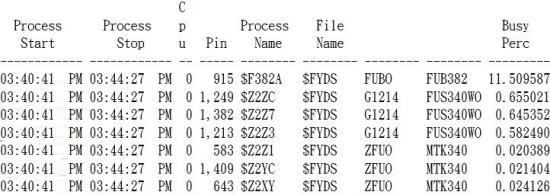
《圖十》
Busy Perc:Process Busy %
註:有些PROCESS 的執行時間極短,Busy 極高,所以BUSY值需要加乘時間因素才能算得真正PROCESS BUSY.
EXCEL公式: =(((HOUR(C2)*60*60+MINUTE(C2)*60+SECOND(C2))/1800)*H2)/2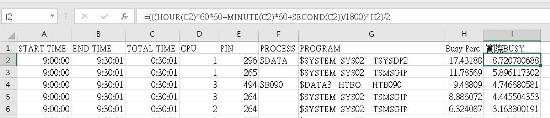
《圖十一》
說明:
(1)將PROC的檔案用EXCEL匯入
(2)產生C欄位(值為B-A;計算實際的秒數)為TOTAL TIME,並將欄位A-C格式改成如下: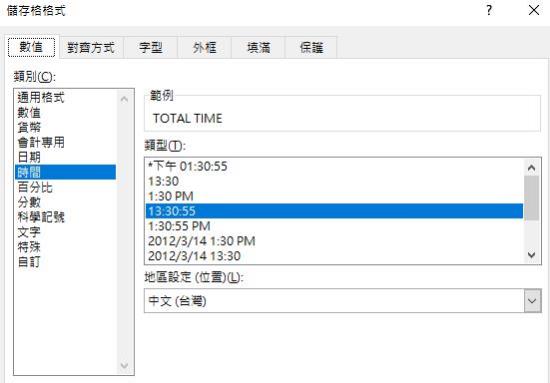
《圖十二》
(3)產生I欄位,設定公式如下:
((process 花費的總時間/收集MEASURE 總秒數)* Proc Busy)/CPU核心數)
=(((HOUR(C2)*60*60+MINUTE(C2)*60+SECOND(C2))/1800)*H2)/2
其中1800是該MEASURE收集的總秒數, 最後一個2是因為該系統CPU 是雙核心要除以2.
十、分析WOPEN REPORT- WDSCOPEN
WOPEN REPORT 是分析DISK上檔案的負載(READs/WRITEs)和Block Splits次數。
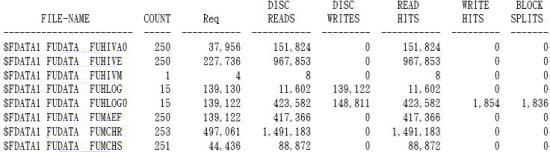
《圖十三》
DISC READS:檔案READ的次數
DISC WRITES:檔案WRITE的次數
READ HITS:檔案在DISK CACHE中READ的次數
WRITE HITS:檔案在DISK CACHE 中WRITE的次數
BLOCK SPLITES:檔案在WRITE時,發生BLOCK SPLITES次數
十一、分析WAIT REPORT- ZDFWAIT
- WAIT REPORT 是分析有發生LOCKWAIT的檔案和PROCESS關係
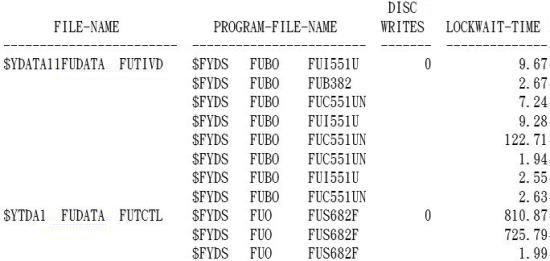
《圖十四》
OCKWAIT-TIME:檔案LOCKWAIT TIME(毫秒ms),若發現有檔案的LOCKWAIT TIME值很高,需請AP人員確認程式對該檔的I/O是否能改善。
十二、分析OPENX REPORT- WOPENX
- OPENX REPORT是分析檔案實際是被那些PROCESS 做READ/WRITE的次數,更能確認檔案主要是被那支程式做I/O
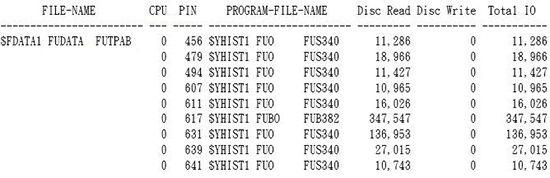
《圖十五》
Disc Read:檔案被Read的次數
Disc Write:檔案被Write的次數
註:每次MEASURE要分析檔案與PROCESS的關係的檔案不同,所以當要分析的檔案不同時,要先修改WOPENX 報表程式的內容,將要分析的檔案放到報表程式內,並重新執行ENFORM程序。
《圖十六》
如何降低TSMSGIP負載
TSMSGIP(Tnet Services Message System Interrupt Process),是系統用來處理message system interrupt,當兩個process 在不同CPU互相交換資料或訊息時,兩顆CPU上的TSMSGIP Process就會處理這些資訊,但若當兩個process 在同一個CPU互相交換資料或訊息時,則TSMSGIP就不會花費CPU資源。
若降低TSMSGIP負載,就能將省下來的CPU資源讓交易程式使用,所以在透過MEASURE分析系統效能時,考量將Process和它主要I/O檔案的DISK放在同一顆CPU,或是將互相關聯的Process放在同一個CPU上,就能降低TSMSGIP對CPU資源的耗損。
分析系統效能程序
一、收集MEASURE
二、先手動分析該時段MEASURE,確認系統最忙碌的時間點
程序如下:
- LIST CPU *
- ADD PLOT CPU-BUSY-TIME
- LIST PLOT
三、調整measoby2和measoby4內容,加上要分析的時間點
+ LIST CPU * , FROM 9:00, TO 10:00
+ LIST DISC $* , FROM 9:00, TO 10:00
+ LIST PROCESS * , FROM 9:00, TO 10:00
+ LIST DISCOPEN * , FROM 9:00, TO 10:00LIST PLOT
四、執行自動分析measure程序A
Run A MDATA -- MDATA為收集的MEASURE DATA
五、會產生八個MEASURE ENFORM REPORT
CPU、CACHE、DISC、IPU、PROC、WAIT、WOPEN、OPENX
六、將IPU REPORT 匯至EXCEL,可產生該時段CPU BUSY的曲線圖
七、檢查CPU REPORT
確認CPU BUSY 是否負載平均.若沒有,就要分析PROC REPORT,確認該顆CPU上的PROCESS 負載較重的PROCESS是什麼,若是DISK PROCESS就要再分析WOPEN REPORT,確認該顆DISK上負載較重的檔案是那些,將它們分散到其他較不忙的DISK上。若是一般PROCESS,就可以進行CPU間PROCESS的調配,以達成系統的CPU負載平均。
八、檢查DISC REPORT
檢查是否有DISK的BUSY過高(大於15),若有的話,分析WOPEN REPORT,確認該顆DISK上負載較重的檔案是那些,將它們分散到其他較不忙的DISK上。
九、檢查CACHE REPORT
確認DISK CACHE的READ HIT 都在95%以上
十、檢查WAIT REPORT
確認是否有檔案LOCKWAIT時間過高.若有檔案的LOCKWAIT 時間明顯過高,將該檔案名放到WOPENX內,重新執行ENFORM/IN WOPENX/產生OPENX的REPORT,確認該檔案是被那些程式做I/O (READ/WRITE).再交由AP人員分析程式行為是否有改善方式。
十一、手動檢查有沒有PROCESS RECV-QTIME過高
若值為2位數,就要分析該程式行為是否正常。
指令: LIST PROCESS *,BY RECV-QTIME,FORMAT BRIEF
十二、調整檔案位置讓DISK的負載分配平均,調整PROCESS分配
讓CPU負載平均,即完成系統效能調校。
十三、若系統資源接近滿載時,就要考量降低TSMSGIP的BUSY
分析方式如下:
A.分析WOPEN REPORT,找出負載最重的檔案。
B.將這些檔案加入WOPENX的程式內,重新產生OPENX的REPORT。
C.找出這些檔案最主要被那個程式所OPEN.交叉比對PROC REPORT。
D.將這些負載過重的檔案DISK的CPU調配和主要程式的PROCESS在同一顆CPU,就能降低兩顆CPU上的TSMSGIP的BUSY。
參考資料
1.Performance Analysis and Tuning for NonStop Systems
2.Measure Users Guide
3.Measure Reference Manual
![]()

