







技術分享
 友善列印
友善列印[產品介紹] Virtualized NonStop效能實測分享
作者/王宜倫
作者簡歷作者擁有22年IT服務資歷,現職凌群電腦NSK服務總處總處長,主要負責台灣證券交易所交易系統與維運系統、NonStop系統維運服務、軟體產品整合服務。專長為HPE NonStop系統、系統整合、系統網路監控管理及專案管理。
前言
HPE於2017年推出採用OpenStack虛擬化技術的Virtualized NonStop (vNonStop) 1.0,並於2018年推出採用VMware虛擬化技術的vNonStop 2.0,可讓用戶依據本身環境需求,選擇適當的虛擬化平台。
凌群電腦也在2018年使用VMware技術建置一套vNonStop 2.0測試系統。此篇效能實測以凌群電腦vNonStop 2.0和HPE新加坡亞太區測試中心的vNonStop 1.0、NS7X1進行效能實測。
測試環境介紹
此次參與測試的三套系統硬體規格與作業系統版本如下:
一、NS7X1 (Gen8/3.5GHz)
- OS : L16.05
- Storage : internal disk (HDD)
- 後續以NS7X1表示
二、vNonStop 1.0 OpenStack (G9/2.0GHz)
- OS : L17.02.00
- Storage : HPE VSA (HDD)
- 後續以vNS1.0表示
三、vNonStop 2.0 VMware (G10/3.5GHz)
- OS : L18.02.00
- Storage : HPE 3par (SSD)
- 後續以vNS2.0表示
凌群電腦vNS2.0 VM佈署說明
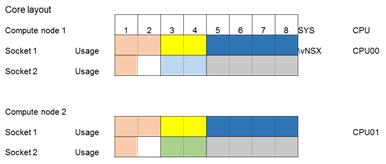
《圖一》
VM分配如上圖所示,採用2個compute node (DL380Gen10),並使用Intel Xeon Scalable Gold 6144處理器,各VM說明如下:
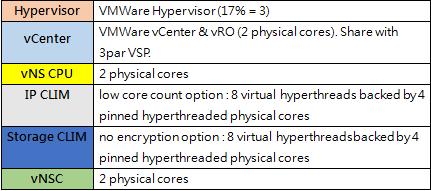
《圖二》
測試案例與結果說明
一、IPC (Inter Process Communication) latency效能測試
- 依照不同CPU、IPU(core)以及訊息長度進行測試
- 每次測試訊息傳送量為10,000筆
- 以C語言編譯,native mode
- 測試變數,分別依照CPU、IPU以及訊息長度做測試驗證
- 相同CPU及IPU(core)
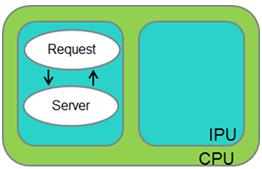
《圖三》
如上圖所示,此測試案例中,Request和Server process執行於相同CPU中的同一IPU。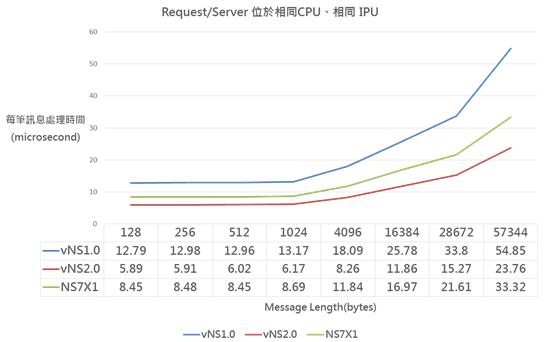
《圖四》
測試結果如上圖表,因process均位於相同IPU且沒有任何I/O,受到VM的干擾最低,效能取決於處理器運算速度,因vNS2.0採用最新且時脈最高的處理器,每筆IPC處理延遲時間最短;而vNS1.0時脈最低,每筆IPC處理延遲時間最長。 - 相同CPU及不同IPU(core)
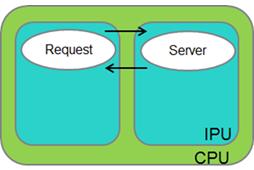
《圖五》
如上圖所示,此測試案例中,Request和Server process執行於相同CPU中,但位於不同IPU。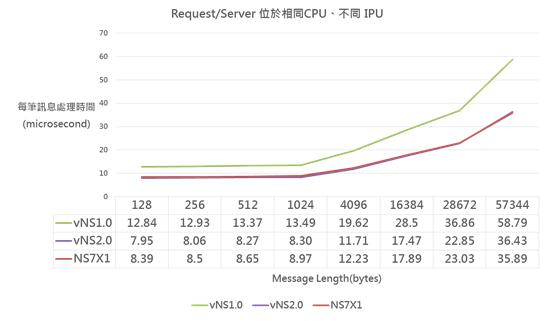
《圖六》
測試結果如上圖表,因process位於不同IPU (vCPU),雖然沒有任何I/O,但仍受到VM的影響,雖然vNS2.0每筆IPC處理延遲時間仍然最短,但與NS7X1相較差距沒有相同IPU的測試大;而vNS1.0每筆IPC處理延遲時間仍最長。 - 相同CPU及不同IPU(core)
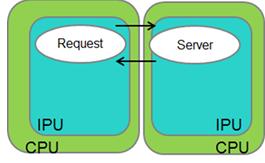
《圖七》
如上圖所示,此測試案例中,Request和Server process執行於不同CPU中,IPC會跨過兩台實體compute node。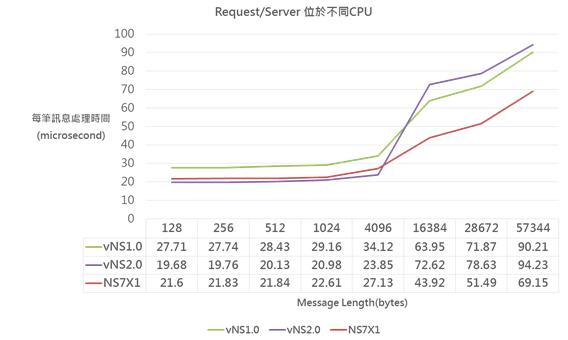
《圖八》
測試結果如上圖表,因process位於不同CPU,IPC會經過實體網路,vNS2.0 IPC為small message (<8KB)時,處理延遲時間仍然最短,但當IPC為large message (>8KB)時,會有顯著拉高,反而最長;此原因為vNS2.0使用的interconnect網卡設定有變動,需配合使用不同的參數,HPE後續會配合調整。
二、TCP/IP通訊傳輸效能測試
- 以C語言編譯,native mode
- 測試變數,分別依照不同訊息長度做測試驗證
- 使用Informatica Ultra Messaging(UM)作為測試工具 (Informatica UM為低延遲高處理容量middleware,提供通訊底層訊息傳輸的控制,用戶可以無需考量socket底層管理,僅需依middleware的回覆作相對應的控制,一方面滿足低延遲高處理容量的需求,另一方面簡化程式開發者的處理)。
- NonStop CLIM端作loopback,不走實體Ethernet網路,單純驗證NonStop TCP/IP與IP vCLIM傳輸效能。
- TCP/IP Latency效能測試
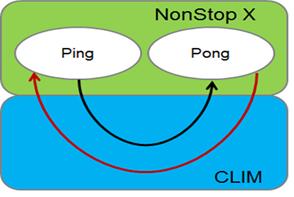
《圖九》
如上圖所示,此測試案例中,採用Informatica UM的測試工具 - ping/pong來量測延遲時間(RTT),每次測試訊息傳送量為10,000筆。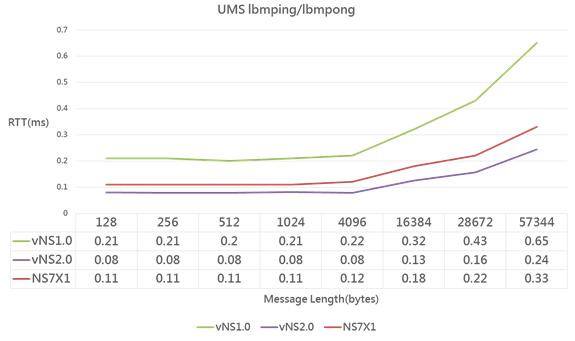
《圖十》
測試結果如上圖表,因vNS2.0的CPU與IP vCLIM均採用最新且時脈最高的處理器,每筆通訊傳輸處理延遲時間(RTT)最短;而vNS1.0時脈最低,每筆通訊傳輸處理延遲時間最長。 - TCP/IP Throughput效能測試
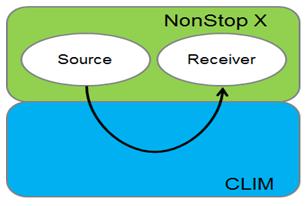
《圖十一》
如上圖所示,此測試案例中,採用Informatica UM的測試工具 - lbmsrc/lbmrcv來量測每秒傳輸處理容量。每次測試訊息傳送量為100,000筆。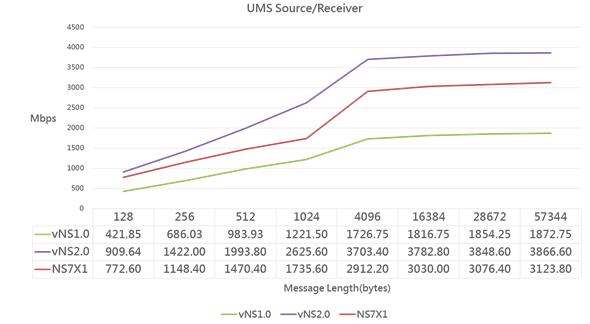
《圖十二》
測試結果如上圖表,因vNS2.0的CPU與IP vCLIM均採用最新且時脈最高的處理器,每秒傳輸量最高;另外,vNS1.0、vNS2.0與NS7X1在傳輸資料長度4KB以上時,每秒傳輸量無顯著增加,已達上限(單一process/session傳輸上限)。
三、Disk I/O
- 針對audit key file隨機存取
- 測試10,000次I/O數
- Record size為100 bytes
- 僅計算I/O時間(不含READ/WRITE process執行時間)
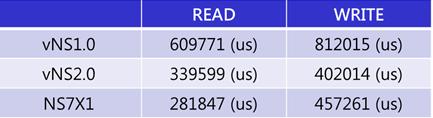
《圖十三》
測試結果如上表,vNS1.0儲存設備採用iSCSI與HDD,無論在READ/與WRITE均表現最差;vNS2.0儲存設備採用iSCSI與SSD,在READ表現略差於NS7X1,但在WRITE表現優於NS7X1;NS7X1儲存設備採用Direct Attach Storage (HDD)。
四、期貨風控處理時間
- 連續送委託進風控處理,計算風控處理每筆委託時間
- 委託量為5,000筆
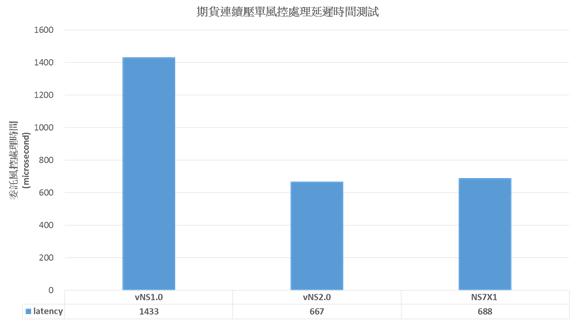
《圖十四》
依據實際應用系統進行測試,vNS2.0效能最佳,每筆風控處理延遲時間約為667us,vNS1.0最差,約為1433us。依據HPE說明,採用相等硬體設備時,vNS1.0的效能約是NS7的0.9倍,vNS2.0的效能約是0.8x倍。此實測數據與HPE的測試數據相符。
結論
測試案例一~三為基礎效能測試,驗證CPU、IPC、disk I/O與TCP/IP通訊傳輸處理能力,可作為相關效能評估參考;實際上,仍應該以應用系統測試當作主要效能參考依據。此次測試驗證經驗分享如下:
- vNonStop與實際硬體配置有高度相關性,VM會有影響,但採用新一代的硬體技術可提高效能。
- NS7採用56Gbps FDR技術,vNonStop採用40Gbps RoCE (RDMA over Converged Ethernet)技術,雖然vNonStop低於NS7,但並無明顯影響。
- 此次測試結果,Disk I/O會是採用vNonStop要調校的重點,vNonStop不具備NS7的write cache enable (WCE)功能,若採用all flash storage,可有效提升效能、降低影響。
- 此次測試結果符合HPE公佈的效能比較數據。
參考資料
- Navneet Aurora, "Performance best practices for vNonStop", 2017 NonStop TBC
- Navneet Aurora, "NonStop 2018 Performance Update", 2018 NonStop TBC
![]()

