







技術分享
 友善列印
友善列印[技術分享] HPE NonStop性能分析與調校
作者/郭哲銘
作者簡歷作者現職凌群電腦NSK服務總處系統工程師,主要負責HPE NonStop證券、期貨、銀行客戶交易系統維運服務、軟體產品整合服務,專長為HPE NonStop系統整合。
前言
HPE NonStop Servers是一款高可用性和可靠性為特點的伺服器,廣泛應用於金融、銀行、電信和其他需要處理大量事務和即時交易的關鍵業務環境。效能分析和調校在HPE NonStop Servers的管理中具有重要作用,目標是最大程度地提高系統的吞吐量、降低延遲,使其更好滿足用戶需求,並確保系統能夠有效地應對高負載和即時需求。

《圖一》
性能分析介紹
一、一般調校程序
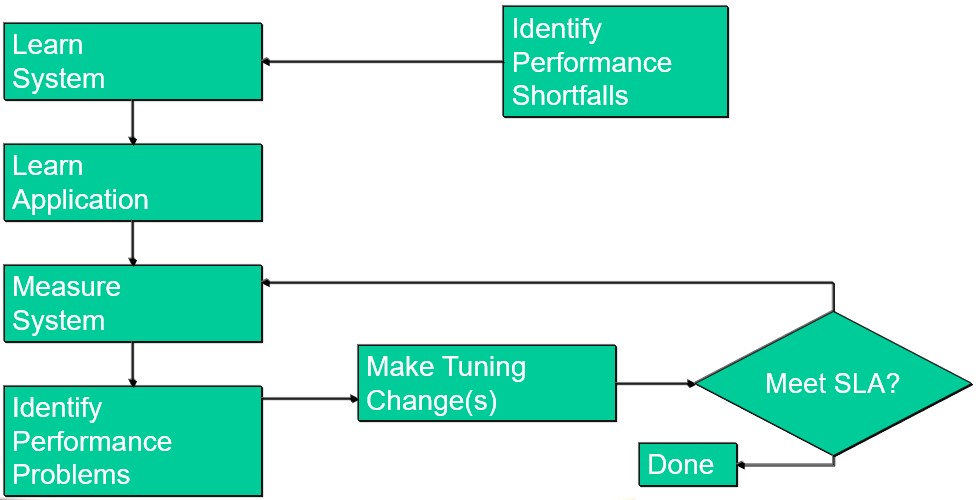
《圖二》
- 辨識效能不足(Identify Performance Shortfalls):首先找出Performance不足的部分,將不足的部分量化 (Response Times、Throughput),並確定SLA需要什麼?例如:正常情況下,95% 的交易在2秒內完成 ; 在月底,90% 的交易在2秒內完成 ; Batch在4小時內完成。(Service-Level Agreement ; 服務等級協定,是技術人員和管理層之間的協議)
- Learn System:學習系統,繪製系統圖,方便識別出系統中可能存在的瓶頸和效能問題。
- Learn Application:學習應用程序(AP),確定關鍵Processes和Files,以及其互動。
- Measure System使用Measure或其他工具取得系統的詳細效能資料。
- Identify Performance Problems:確認是否偵測到任何異常、瓶頸或配置不良的跡象。
- Make Tuning Changes:盡量一次只更改一個部分。
- Meet SLA:如果滿足SLA,就完成了。如果未滿足SLA,則重新Measure並繼續調整。
二、基本調校原理
HPE NonStop Servers Disk Subsystem是最常見的初始瓶頸,Response times廣泛變化通常是由系統最慢的設備 (硬碟) 引起,因此建議先最小化Disk的使用率,再來平衡CPU使用率。
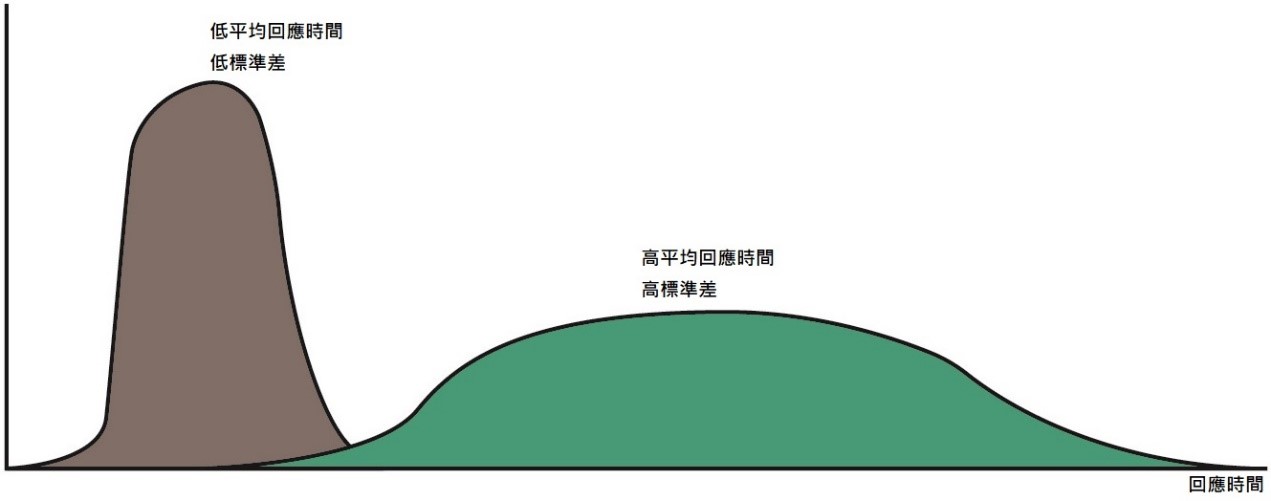
《圖三》
許多SLA都是根據 ‘平均回應時間’ 指定,對許多用戶來說,一個經過良好調整的系統應該要如上方左側的窄曲線圖,平均回應時間較低且標準差也低,可說明系統中沒有重大的瓶頸,為較理想情況;反之右側的寬曲線圖,高平均回應時間、高標準差,因為其高度的可變性,表明存在主要瓶頸,是不理想情況,較長的反應時間意味著有較長的Queue,這時就需要對系統進行效能調校。
排隊理論(Queuing Theory)
一、Queuing理論
排隊理論是研究排隊系?行為的數學理論,它涉及到許多影響排隊系?性能的因素,HPE NonStop Servers上的Queue行為和排隊理論非常接近,Response time (Request的總時間) 取決於Service time和Queue time:
Response time = Queue time + Service time
Queue time也稱為Wait time – Request在排隊中等待,直到被服務的時間長度。
Service time – Request離開隊列後,在服務內執行的時間。
影響排隊理論的六個主要因素如下:
- 到達模式:Request進入系統的方式和時間分佈,可以是隨機的、有規律的或其他模式。
- 服務模式:系統如何處理請求,包括服務的時間和方式,這可以是隨機的、有規律的或其他模式。
- 伺服器數量:系統中可用的伺服器或處理單位的數量。
- 到達人口:可以進入系統的請求數量。
- 排隊長度:系統中等待處理的請求數量。
- 加入優先權:系統的事物或請求之間的優先順序。
將這些因素應用於特定的系統組態中,可以有不同的設定:
- CPU in OLTP:Random/ Random/ 1/ Infinity/ Infinity/ Priority
- CPU in Batch:Constant/ Constant/ 1/ Finite/ Infinity/ Priority
- Disc in OLTP:Random/ Uniform/ 1/ Infinity/ Infinity/ Priority
二、隊列長度與使用率 (Queue Length Versus Utilization)
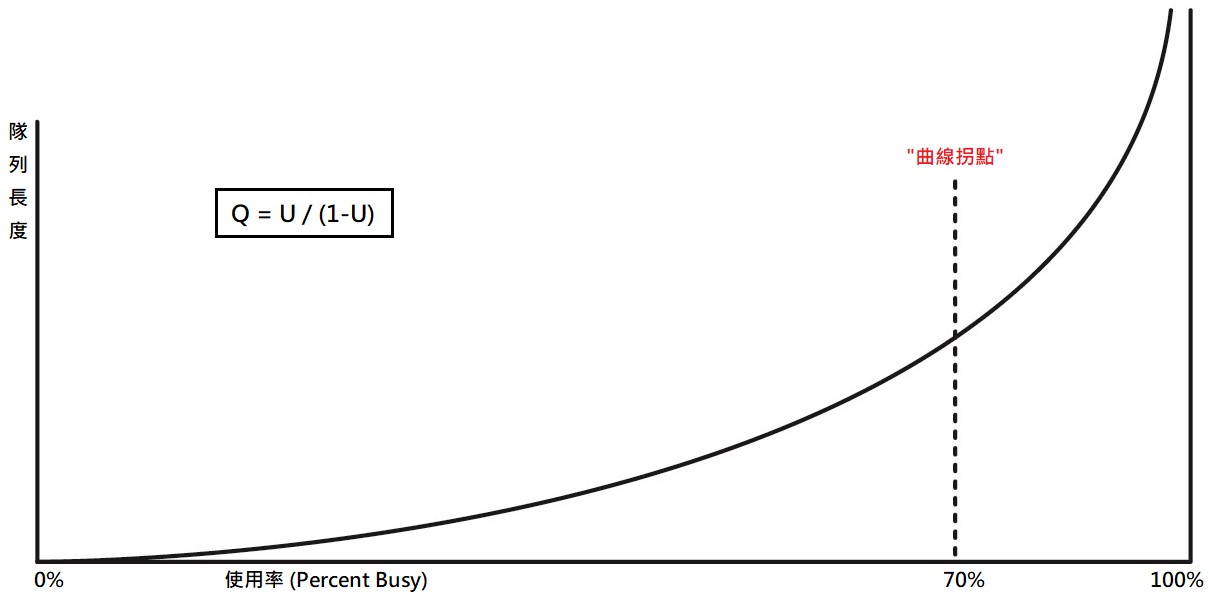
《圖四》
這是排隊理論中最基本的曲線和公式 (M/M/1的假設),到達模式和服務模式都是隨機 (M),並且遵循指數分布,這意味著請求到達和服務時間之間的間隔是隨機的,不受前一個到達或服務時間影響,並且只有一個服務設備提供服務,系統中不會有多個並行的服務通道,請求必須依次排隊等待被服務。
基於這些假設,M/M/1模型可以用來計算排隊理論的一些關鍵性能指標,任何設備的使用率和隊列長度之間的關係如上圖所述,當設備的使用率增加,隊列長度呈線性緩慢增加,隨著通過「曲線拐點」而隊列長度呈指數迅速增加,「曲線拐點」的使用率約為70%,所以使用率應該盡量保持在曲線拐點的左側,也就是不超過70%。
下方列出曲線所描繪的數學公式Q = U/(1-U):
- U = 20% Q = 0.25
- U = 40% Q = 0.67
- U = 50% Q = 1.0
- U = 60% Q = 1.5
- U = 70% Q = 2.3
- U = 80% Q = 4.0
- U = 90% Q = 9.0
- U = 99% Q = 99.0
三、相對反應時間與使用率 (Relative Response Time Versus Utilization)
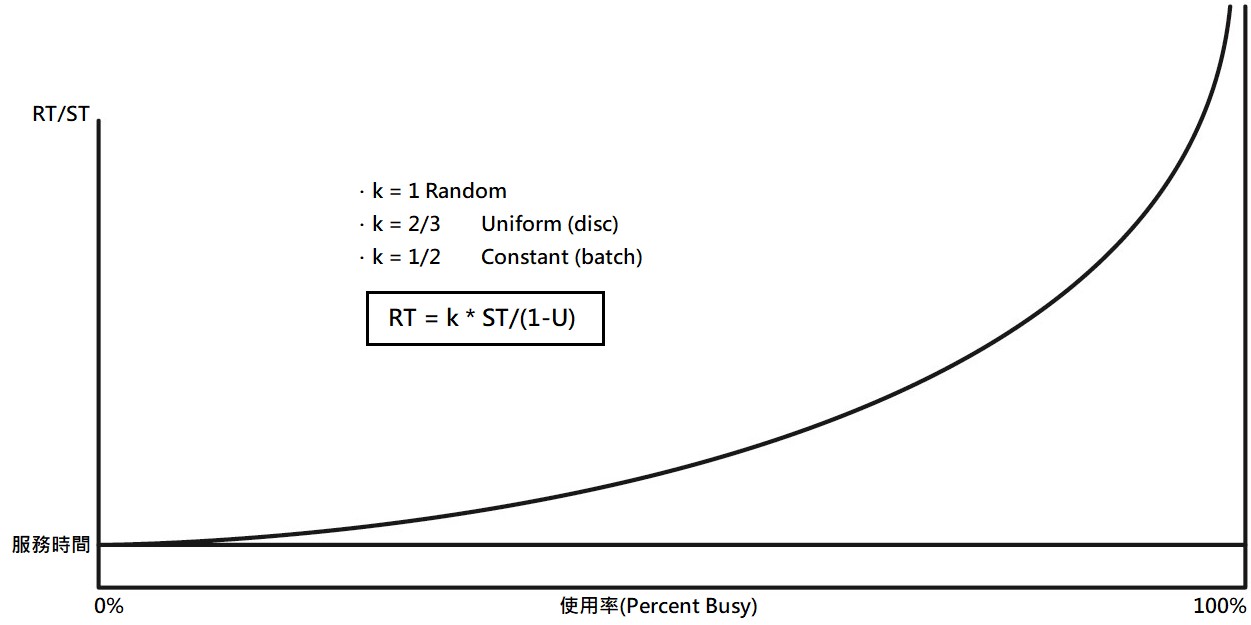
《圖五》
這個公式的基本含意為,當系統的使用率 (U) 較低時,即系統中的服務通道較少被占用,相對反應時間 (RT) 會比較小,請求和作業通常不需要等待太久就可以被服務,圖中顯示服務設施的回應時間相對於其服務時間如何增加,X軸為使用率,Y軸是反應時間與服務時間的比率 (RT/ST),所以當曲線是服務時間高度的兩倍時,反應時間是服務時間的兩倍。
這個公式在效能分析和優化中經常被使用,可以幫助系統工程師了解系統在不同負載下的性能表現,並且可以根據系統的使用率來調整系統的配置和資源分配,以提高系統效能。
反應時間是兩個因素的函數,設施的服務時間及其目前的使用率水準:
‧服務時間取決於設施類型和請求的性質。
‧使用率是動態的,取決於目前的請求。
這個曲線是通用的,對所有服務設施都有效,一旦我們從相對反應時間轉向絕對反應時間,曲線就會根據服務設施的速度而變化。
下方列出曲線所描繪的數學公式RT = ST / (1-U):
- U = 20% RT = 1.25 * service time
- U = 40% RT = 1.67 * service time
- U = 50% RT = 2.00 * service time
- U = 60% RT = 2.50 * service time
- U = 70% RT = 3.33 * service time
- U = 80% RT = 5.00 * service time
- U = 90% RT = 10.0 * service time
- U = 99% RT = 100 * service time
四、實際反應時間與使用率 (Actual Response Time Versus Utilization)
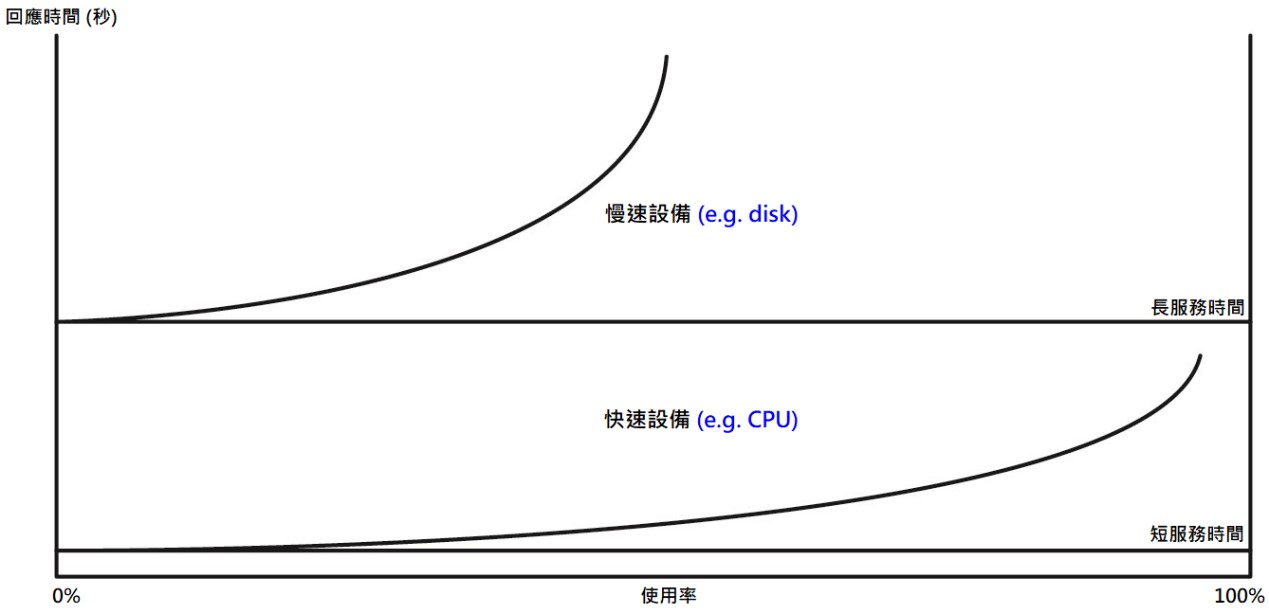
《圖六》
這張圖表顯示實際設備的回應時間與使用率的關係 (下方是快速設備CPU、上面是慢速設備Disk)。
快速設備 (CPU),因性能較高,系統能夠更快地處理服務請求,減少了請求等待的時間,隨著使用率的增加,實際回應時間呈指數成長,但因為服務時間較短,在50% busy時,CPU的回應時間是其服務時間的兩倍,但由於服務時間很短,因此回應時間也很短。
慢速設備 (Disk),特別是在需要頻繁進行I/O的情況下,隨著使用率的增加,實際反應時間呈指數成長,這種成長又與長時間服務有關,在50% busy時,硬碟的回應時間是其服務時間的兩倍,這表示反應時間也很長。Disk反應時間的「曲線拐點」約在70%,在90% 的情況下回應時間是其服務時間的10倍,也意味著效能下降了10倍,這就是為什麼說Disk是NonStop中最常出現的初始瓶頸。
從這些理論中可以得知,快速設備的使用率可以達到或超過曲線的拐點,而對反應時間的影響很小。慢速設備的使用率必須維持在曲線拐點以下,以避免反應時間的嚴重損失。
參考資料
- Measure Reference Manual
- Performance Analysis and Tuning for NonStop Systems Student Guide
![]()

