
第242期 / December 5, 2017 |
機器學習-以Kaggle競賽Titanic資料集實作作者/蘇志民 [發表日期:2017/12/5] 前言 現今人們在生活中都希望所有事情都能夠自動化,或是有一套能夠幫你預測、提供建議的系統,因此人工智慧的議題也是不斷的再演進及被提出,其中機器學習是實現人工智慧的途徑,機器學習主要的定義是透過過往的經驗,訓練出一個模型,看到未知的資料輸入模型後,可以預測出結果的一個過程,且可以不斷的改進,而要往這個過程前進,要透過一連串的如必須先了解資料,做資料清理,選擇合適的演算法,調整訓練的參數,最後要進行驗證等等,實作的小節會再提到。 相關資料 一、監督式學習及非監督式學習 機器學習裡主要又分為兩種學習方式,監督式及非監督式學習,其區分的方式為,監督式學習是透過訓練資料(Training Data)建立模型,測試資料(Testing Data)再透過這個模型預測結果,訓練資料是已被標註結果的資料集,而非監督式學習是訓練資料沒有被標註結果,透過現有的資料建立預測模型。 二、Python語言及相關套件 Python是常被拿來作為資料處理的程式語言,因為其對矩陣運算的彈性非常方便,也有許多的套件可以使用,如scikit-learn及pandas,這兩個套件在實作機器學習上會有很大的幫助。 三、Kaggle競賽 Kaggle是一個資料分析的競賽平台,各個企業可以提出問題與資料供大眾進行分析,有些還會提供獎金吸引參賽者的互利模式,是一種群眾外包,進而找出解決問題的平台。 實作 本節將Kaggle競賽中的Titanic資料集進行實作,以預測乘客是否生還。 一、Kaggle Titanic 首先至Kaggle Titanic(https://www.kaggle.com/c/tita)下載資料,有train.csv與test.csv,在分析前,必須找出有用的特徵,與其相關性,如本次的資料是乘坐鐵達尼的乘客存活與否資料,訓練資料內已經被標註結果,因此是屬於監督式學習,演算法選擇可以二分法的即可,如回歸分析,接下來則是要開始進行資料部分,資料的欄位如下: 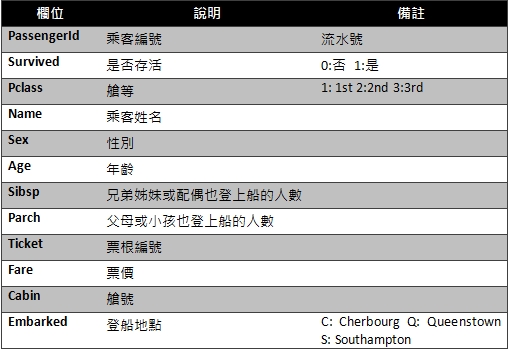 列出所有欄位後,可以大概看出哪些會跟存活率沒關係的,如姓名、票根編號、艙號、登船地點可能不用考慮,但其他都可能跟存活有關,要看相關度的話,則要進入分析特徵的階段,當然也可以用很詳細的統計方法去計算,但本篇先以簡單的方式判斷。 二、環境建置 本篇以python及IPython notebook介面實作,以pandas的函式庫處理資料,matplotlib 可以產生統計圖,python版本為2.7.11,以virtualenv建置虛擬環境,使得開發的環境可以分離,不會受到全域環境的影響,首先安裝python後,使用pip install virtualenv安裝,之後再使用virtualenv .env指令,產生目錄下一個資料夾為.env,並會安裝獨立的python環境在此資料夾下,而要使用虛擬環境時,須執行.env/Scripts/activate指令,便能在這個虛擬環境下進行操作。 最後使用pip install pandas、pip install jupyter、pip install matplotlib、pip install scikit-learn安裝相關會用到的函式庫。  三、分析特徵 建置完環境並進入後,執行jupyter notebook指令,將python notebook的介面叫出來,在畫面上找new > notebook就能建立一個新的python互動介面,可以直接在web上撰寫python程式,按ctrl + enter執行。 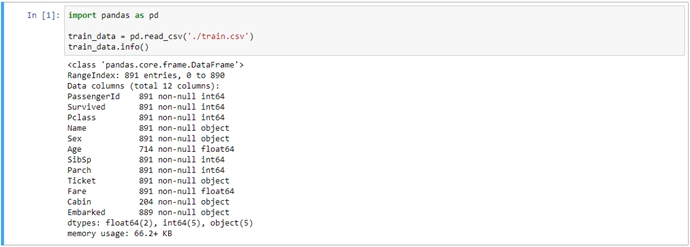 根據上圖透過pandas載入資料成為dataframe後,可以先看資料的屬性,共有891筆,但有些欄位如年齡是不完整的,須做一些處理,如補零或是放全部資料年齡的平均值。 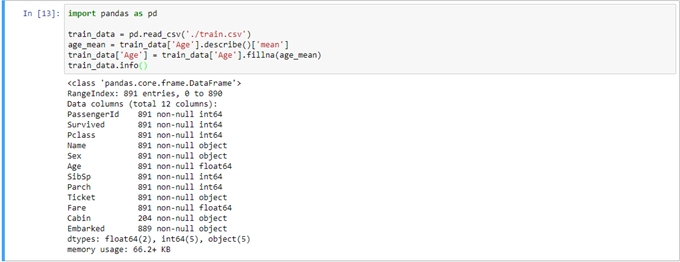 透過上圖的dataframe.describe()指令,可以取得許多統計的屬性,如平均值、標準差等,這裡先取用年齡的平均值,並將其值插入至Age為空的欄位中,以dataframe.info()檢查是否都已經插入完了。 接下來就可以開始找感興趣的特徵,檢視特徵與存活的關聯性的強弱。 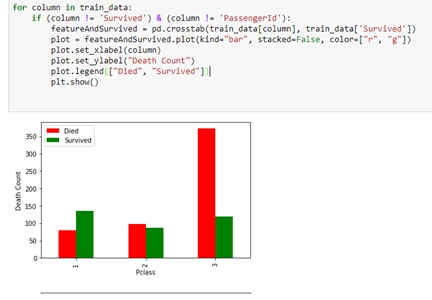 以上的程式可以將存活與特徵劃出直方圖,藉此可看出資料中特徵與存活的關係,如圖中是艙等(Pclass)欄位,可看出1的存活比率較高,而3的死亡率較高,因此可以簡單地透過此種判斷,決定這個特徵是否會影響結果,進而加入訓練資料的維度。 下一步是將資料透過機器學習演算法,計算出一個模型,供測試資料使用,執行以下指令載入scikit-learn的函式庫: from sklearn import cross_validation from sklearn.linear_model import LogisticRegression from sklearn.metrics import classification_report, confusion_matrix, accuracy_score 由於scikit只支援數字,因此要將性別欄位的值轉換成0或1: 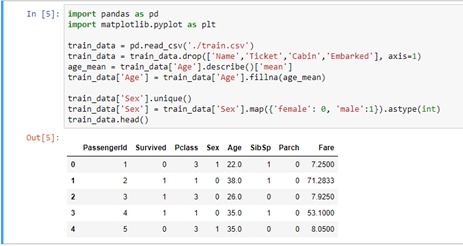 接著將訓練資料中的存活欄位單獨取出,與選取的特徵欄位資料分開,如範例所示,將拿Pclass、Sex、Age三個欄位作為訓練: 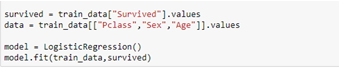 如此一來就有一個迴歸分析的模型了,接下來是載入測試資料,並做相同的資料清理: 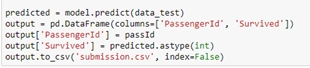 以上程式是用訓練後的模型,去預測測試的資料,並將測試資料匯出成Kaggle上所接受的欄位格式,就是只有PassengerId與存活與否的欄位,並會計算分數:  點選Kaggle平台上的Submit Predictions,即可將剛剛預測出的資料上傳,平台會將對結果評分,滿分是1。  可以看到效果並沒有很好,可能就要繼續從資料挖掘出一些模式,修正特徵值,或調整演算法的參數或更換演算法等等,就能繼續改進資料訓練的準確度,如可以將訓練資料中無年齡的資料列去除,因為有100多筆,可能會影響到預測的準確度。   可以看到上圖,分數改進了一點點,不過還不夠完美,因此可能需要更完善的統計分析方式,或是將年齡切為級距如0-10歲的生存率、11-20歲的生存率等,或挑選其他的演算法嘗試,以上就是這次的機器學習實作。 參考資料 1.監督式學習 2.Kaggle 3.[Python] pandas 基本教學
|

|
凌群電子報/一九八四年五月二十日創刊 |