
第205期 / November 5, 2014 |
高效能序列化的Google Protocol Buffers作者/簡宗宇 [發表日期:2014/11/3] 前言 序列化(Serialization)是將資料轉換為可傳輸或是可保存的格式,而序列化的還原即稱為反序列化(Deserialization)。為什麼要序列化呢?比如在資料傳遞前,原本要傳遞的資料是以物件的型態存在記憶體中,然後將資料物件依照編碼方式轉成字串或XML等資料格式,接著透過傳輸機制送達到對方,對方收到後,在依照編碼規則寫入至資料物件,再進行後續的處理,但如果可以直接將資料物件透過序列化處理,然後傳遞到對方,對方收到後,經過反序列化程序後即可取得原本的資料物件,不僅簡化程式邏輯,也因序列化後的資料封包變小而讓傳遞速度變快,而且也省去了編碼的過程與可能轉換的問題,整體速度上與程式結構上都帶來極大的效能與方便性。 現今資料傳遞方式涵蓋了通訊協定的複雜性,使程式開發人員可以不需要關注網路通訊的細節,而是將更多的時間和精力放在商業邏輯的實現上,並且提高程式開發的效率,但是在現今的環境下,網路傳輸、頻寬與硬體的設備隨著時間改善,因此傳遞資料量越來越大,或是越來越複雜,所以不再只是追求能夠將資料互相傳遞就好,而是為了能夠達到即時傳遞與接收大量且複雜的資料,勢必需要強化序列化的效能,所以高效能序列化將是未來必須解決的問題之一。為了實現簡單物件存取,以及解決資料傳遞的容錯性、擴展性、安全性、性能…等等的問題,W3C推薦使用XML,JavaScript的利用子集JSON,原生語言也推出各種序列化的API,Google推出了Google Protocol Buffers…等等,以上都是為了資料傳遞所開發的方法與框架。其中Google Protocol Buffers就是Google實現數據存儲和傳輸格式的一個核心的基礎。以下本將陸續介紹XML、Json與Google Protocol Buffers的原理以及各項的優缺點,最後序列化比較及結論。 一、XML 可延伸標記式語言(XML),是一種中介標籤語言(meta-markup language),是由一些特殊字碼(code)或控制標籤(tag)所組成,它們單獨存在時並無任何的意義,而需要特殊的軟體經由一定的規則解讀後由文件輸出,所以它們可以使文件更加具有結構性。 XML是由程式開發人員自己自由決定的標籤式語言如《圖一》, XML格式是有三個必須遵守的格式:
2.標籤之間不得交叉使用。 3.所有屬性都必須被涵蓋於引號,如《圖一》。  《圖一》XML範例
二、JSON JavaScript物件表示法 (JSON),是一種輕量級的資料交換語言,以純文字為基礎,附屬於 JavaScript的一種物件描述方法,不但可以透過特定的格式去儲存任何資料,包含:字串、數字、陣列、物件,也可以透過物件或陣列來傳送較複雜的資料,而且易於人閱讀和編寫,也易於機器解析及生成。它基於JavaScript Programming Language, Standard ECMA-262 3rd Edition - December 1999的一個子集。JSON採用完全獨立於語言的文本格式。 JSON主要利用了成對的{}來包住各個物件,且每一個物件的名稱後面跟一個冒號來表示該物件的內容,每一個物件之間使用逗號分隔,如《圖二》。每一個物件中使用成對的[]來包住每一個陣列,每一個陣列之間也是使用逗號分隔,如《圖三》。。每一個陣列中的資訊內容使用成對的""來包住,其中資訊內容可以是文字、數字、物件、陣列與布林函數,如《圖四》。。透過圖一的資訊進行序列化如《圖五》。。  《圖二》JSON物件  《圖三》JSON陣列 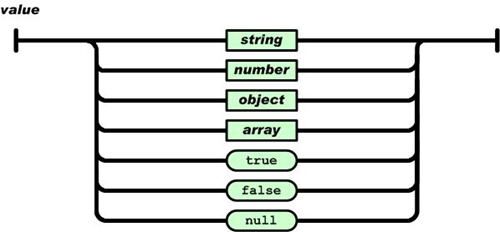 《圖四》JSON資訊內容  《圖五》JSON範例
三、原生語言的序列化功能 Java/.Net語言本身內建了序列化API,下面我們以.Net為例,可以分成兩種方式,其一就是XML序列化,將資料序列化轉換成 XML文件,優點就是可以從不同作業系統或不同的程式語言經由XML文件將資料還原序列化,缺點就是序列化與反序列化的速度較慢。. 其二為二進位序列化,使用二進位編碼方式,產生二進位型態的序列化,相較之下,此種序列化比上述XML序列化更加有效率,因為無須再依據XML格式進行轉換,可惜無可讀性而且只能讓.NET Framework的應用程式進行反序列化,所以在選用原生語言的序列化功能時,要先確認使用對象與目的。 四、Google Protocol Buffers 在Google這樣的大規模應用以及操作商業資料是非常重要的,如何高效率傳遞資料且簡潔又可擴充性的文件表示呢?為了解決上述的問題,Google於2008年開始提供了Google Protocol Buffers簡稱Protobuf,一種高效能的序列化格式,可以用於跨Process的資料傳遞,原本是Google公司內部混合程式語言的交換中介,目前已經正在使用的有超過 48,162 種格式定義和超過 12,183個 proto 文件,該文件是對資料物件的一個描述,包括欄位名稱、類型、位元中的位置,此技術是Google中一個比較核心的架構,作為分散式運算以及涉及到大量不同商業資訊的傳遞。 Protobuf實現的資料存儲和傳輸格式,類似於XML、JSON…等,但又更有效率,且編碼耦合性低,使用方便,格式也相當的靈活,其中就目前為止,開發工具以及跨語言的支持也都相當成熟,其最大的特點就是傳遞的資料是以二進制數據格式,雖然是二進制,但並沒有因此變得複雜,程式開發人員只要按照一定的語法定義資料結構,針對不同的資料去定義不同的資料型別,如《圖六》,然後輸入命令將文件送給編譯工具,編譯工具將自動生成相關的類別,通過將這些類別包含在各個項目中,可以很輕鬆的調用相關方法來完成商業資訊的序列化與反序列化工作,資料經過序列化後會成為一個一個二進制,所有二進制成為一系列Key-Value的Message Buffer, 對於 Key-Pair 結構無需使用分隔符號來分割不同的 Field,如《圖七》。 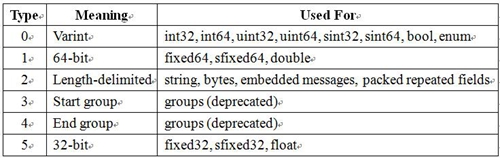 《圖六》文件資料結構 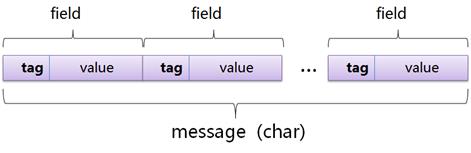 《圖七》Message Buffer Protobuf序列化後所產生的二進制資料緊湊且密集,其中巧妙利用了Encoding方法即Varint,此方法是一種二進制表示法來換算成數字。用一個或多個字來表示一個數字,值越小的數字使用越少的字數。這能減少用來表示數字的字數。比如對於整數的資料類型類型(Int32),一般來說需要 4 個 byte 來表示。但是採用Varint,對於很小的整數類型的數字,則可以用 1 個 byte 來表示。但是Varint就像雙面刀一樣,若數字很大時採用 Varint 表示法,那麼就需要大於4個 byte 來表示。可是一般狀況來說所有資料的數字不可能全部都是很大的數字,因此大多數情況下,採用 Varint 後,可以用更少的字數來表示數字資訊。Varint 中的每一個 byte 第一位置的bit具有特殊的含義,如果第一個位置為 1,表示後續的 byte 也是該數字的一部分,如果第一個位置為 0,則結束,其他的 bit 都用來表示數字。因此小於 128 的數字都可以用一個 byte 表示,大於 128 的數字,比如 172,會用兩個byte來表示:1010 1100 0000 001,如《圖八》。 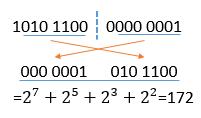 《圖八》Varint Encoding Protobuf如何撰寫?一般來說先將proto文件定義需要傳送的物件內容,以上述XML與JSON相同的例子,把Syscom公司當為一個物件,並且定義好部門、姓名、編號、性別、公司與手機的資料型別,如《圖九》。由傳送端將資料寫入物件再進行Protobuf序列化並且進行傳遞,傳遞方式可用Socket、IPC…方式,如《圖十》。最後再由接收端將接收到的資料反序列化後直接為Syscom物件,如《圖十一》。可以從《圖九》至《圖十一》看出,Protobuf在操作上較其他序列化格式更加容易開發,有了Protobuf機制,萬一將來需求發生了一些變更,比如說,需求要再增加一個欄位,那麼也只需要在message Syscom中增加一行程式,對於傳送端或是接收端來說,也是只需要增加一行寫入/讀取的程式,不必去搜尋文件的資料結構,再把想要新增的欄位加入該結構中,與XML或是JSON…等等的文件比較上更是輕鬆多了!。  《圖九》定義proto文件  《圖十》傳送端  《圖十一》接收端
五、各種序列化比較 以下根據各種資料傳遞方式如Protobuf、JSON與XML進行比較,其中包含讀取寫入以及檔案大小為主。根據《圖十二》可以非常清楚看到Protobuf讀取文件的速度最快,而Json讀取文件的速度最慢。Protobuf寫入文件的速度也是最快,而Json寫入文件的速度最慢。將讀取與寫入速度共同統計可以看出Protobuf的耗費時間最短且效率是最好的。在相同的對象所生成的文件的大小比較,Protobuf的是最小的,XML是最大的,最重要的序列化與反序列化也可以明顯看出Protobuf占了絕大部分的優勢,快過於JSON 5~8倍的時間,以及快過XML 9~11倍的時間,為什麼會快這麼多呢?其實在於Protobuf的特性是將物間序列化成二進制,反序列化時是直接轉化成物件,不需要再從文件中讀取出Node,轉換成內部的結構後再轉成物件,所以速度當然會快上許多,而且撰寫程式也是相當的簡潔,不在像以往的XML與JSON,必須撰寫一大堆自訂義的資料結構再進行序列化與反序列化。 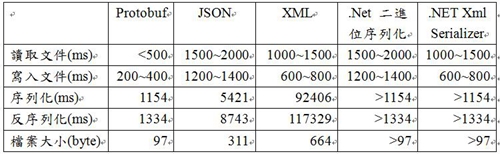 《圖十二》比對資料 結論 為了實現快速序列化與反序列的將資料傳遞,如果使用XML或是JSON…等方式,雖然可以輕鬆閱讀文件內容,卻是非常佔用檔案空間,而且序列化與反序列化會嚴重影響效能,造成讀取或寫入時耗用更多時間。所以為了資料傳輸需要高擴展性、高效能、自動化…等等的這類問題,Google Protocol Buffers是較佳的解決方案,但目前商用資料傳輸的格式仍以XML為主流,例如Open Data,為什麼XML仍是主流呢?儘管Google Protocol Buffers不管在哪一方面都遠勝過XML,但卻無法廣泛的使用,因為將序列化的文件無法統一化,也就是說不管是Server或是Client屬於不同的序列化方法便無法讀取資訊,及因為Protobuf幾乎無法人為閱讀,造成如果資料錯誤,無從判斷發生錯誤的位置,即使Protobuf目前有這些缺點,目前仍在Web Services佔上了一席之地,說不定未來Open Data也使用Protobuf來進行傳遞。 Google Protocol Buffers是迄今為止,資料傳遞的序列化與反序列化之速度和檔案大小是最好,一般來說文件必須預先定義,但Protobuf支援了動態編譯,可惜Protobuf目前只適合傳輸量較小與允許自定義類型的場合使用。Protobuf擴充相當方便,只要遵守一些規則便可向前向後兼容。當然它的能力不僅僅限於簡單的資料傳遞和序列化與反序列化,它最主要特徵是提供了反射能力,可以被動式的指定資訊內的所有片段,並且操作,而不需要編寫任何特定程式,此功能便可以很方便地與其他格式進行轉換,利用此功能使程式開發人員可以依據需求,選擇合適的資料表達格式作為開發工具。在現行許多Web的應用程式已開始廣泛使用Google推行的Protobuf作為資料傳遞的格式,成為另一種使用廣泛的中介資料交換格式。 參考資料 1. http://en.wikipedia.org/wiki/Remote_procedure_call 2. http://en.wikipedia.org/wiki/XML 3. http://yes.nctu.edu.tw/lecture/web/xml/intro/ 4. http://en.wikipedia.org/wiki/JSON 5. http://www.json.org/ 6. https://code.google.com/p/protobuf/ 7. http://en.wikipedia.org/wiki/Protocol_Buffers
|

|
凌群電子報/一九八四年五月二十日創刊 |