
第198期 / April 5, 2014 |
淺談資料分析的價值與應用作者/梁孝平 [發表日期:2014/3/14] 前言 全球市調機構IDC預測,Big Data市場規模從2010年的32億美元不斷飆升,到了2015年將高達169億美元,年平均成長率接近40%,IDC和全球儲存設備大廠EMC共同發布報告指出,未來十年,企業將管理50倍以上的資料量。 尤其,Big Data不像雲端運算僅止於科技業,其影響範圍遠超出企業層面,從政府、醫療保健、學術單位到消費性產業等領域,皆能看到其後續效應,而數據大戰引爆的兆元商機,除了將改變傳統的公司經營模式,另一項重大改變是,企業決策者要開始思考如何運用軟、硬體,從各種數據中淬煉出有用的價值,簡單來說,以電信業者為例,若能從數以千計的客戶資料中找出消費行為模式和市場趨勢,再將分析結果賣給需要的企業,就是另一種資料經濟。 何謂資料分析? 資料分析的目的簡單來說是把隱沒在一大批看來雜亂無章的數據中的訊息集中、萃取和提煉出來,找出所研究對象的內在規律。已現今的時代來說,像是當你連上臉書按讚打卡、上傳照片到網路相簿與朋友分享、上班收發e-mail、用悠遊卡買杯咖啡、透過ATM領錢、走進大賣場刷卡購物、甚至是進家門開燈,都是在源源不斷的創造資料,但是在過去,資料量太大、毫無價值的資料太多,使得沒有一家企業願意去投資或應用過去既有的流程來一一過濾所有的資料並對資料進行挖掘其潛在價值,而在過去視為糞土的大量雜亂資料,在現今科技與分析工具進步的時代進而跳脫成為大家爭相競爭的黃金領域,也就是現在火紅的Big Data的概念。 套用一位著名資料庫專家,曾經獲得有電腦界諾貝爾獎之稱的圖靈獎 (Turing Award)的 Jim Gray所述,科學發展已經走過了「實驗、理論、計算」三個階段,而進入了第四個以「資料」為重點的階段,也就是他所稱的第四典範。過去幾十年來是計算科學大行其道的時代,各種重要的資料庫技術和演算法,都在過去幾十年漸漸成熟;而現在由於全世界物聯化 (instrumented) 以及互連化 (inter-connected) 的關係,讓全世界的資料在任何領域都以非常快的速度在累積,而且累積的速度遠遠超過現在所有企業所能處理的速度。由於資料累積的量和速度都是前所未見,而且其中的確蘊含寶貴的資訊金礦,因此在科學研究或是其他各種領域,大家都轉而以資料分析來為科學研究或是企業組織提供發展方向、尋求突破。 因此像Big Data這個從資料探勘(Data Mining)延伸出來的概念,重視的不在於分析技術的進步,而是在這些大量資料本身所隱藏的資訊,以及提供人們對於各種現象各種不同的解讀方式及預測能力。「樣本=母體」的時代不僅突破了傳統統計學在取樣以及分析上的侷限,資料展現的「相關性」(非拘泥於直接的「因果關係」)經常帶來意想不到,但十分符合邏輯,且有用的發現。 資料分析五部曲(以Big Data為例) 根據維基百科的定義,海量資料(Big Data)【稱為巨量資料或大數據】指的是所涉及的資料量規模巨大到無法透過目前主流軟體工具,在合理時間內達到擷取、管理、處理、並整理成為幫助企業經營決策更積極目的的資訊 。根據 IBM 的說明,海量資料有四個特性,亦稱為海量資料 4V ,亦即資料量龐「大」(Volume)、變化飛「快」(Velocity),種類繁「雜」(Variety),以及真偽存「疑」(Veracity)。換言之,海量資料其實就是資料(Data),只是處於現在資訊網路時代,這些資料特性變的又多、又快、又雜,又真偽難分。 而從情報理論(Theory of Intelligence)來看,資料的運用到實際決策(Decision Making)尚有一段距離,其中決策即是實際將資料用於行為前的判斷,如圖一所示。一般而言,資料到決策的運用中間尚包括兩步驟,分別為資訊(Data)與情報(Information)。資料屬於外部,亦是未處理之原始資料;資訊即是結構化處理後的資料,通常為內部文件。 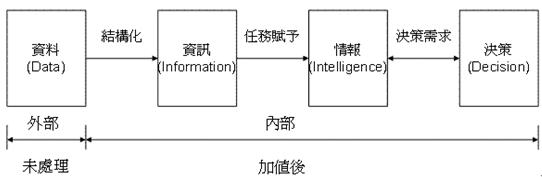 《圖一》情報理論架構 從國際資訊大廠Oracle定義,海量資料分析循環包括擷取(Acquire)、組織(Organize)、分析(Analyze)與決策(Decide)等四步驟。運用海量資料的目的與情報循環之目的一樣,均是用於支援決策並找出新商機。對造兩者間關係,蒐集步驟對應到擷取步驟、處理步驟對應到組織與分析步驟、運用步驟對應到決策步驟。結合兩者,可以得到海量資料分析五部曲 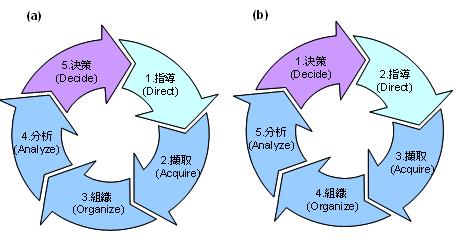 《圖二》 指導即是規劃(Plan),規劃海量分析所要擷取標的、組織方式、分析模式與支援決策內容。指導是海量資料分析的關鍵。資訊處理要避免GIGO(garbage in, garbage out)的關鍵就在規劃階段。在情報理論實踐中,規劃與指導通常由資深情報官負責,在海量資料分析中亦然,若沒有深厚的產業實務經驗,將無法取得有意義的結果,更遑論分析資料後所得的洞見(Insight)。 指導步驟的產出(Output)是擷取與組織步驟的起點。鑑於海量資料分析通常包括異質(Hybrid)資料,因此資料擷取,組織與儲存,需要有特殊考量。需要說明,若以情報理論來說,組織步驟通常與分類結構相關,如何建立易於分析的分類結構與資料,是海量分析效能的關鍵。 分析是海量資料處理的另一關鍵。簡易的分析是包括找出所定義範疇不同物件的關係,例如一個著名的範例是Wal-Mart透過帳單分析,找出啤酒、紙尿布與星期五銷售之關連性,透過將啤酒與紙尿布放在一起販賣,提升了啤酒的銷售量。在此案例中,範疇是清楚的(啤酒、紙尿布、星期五與帳單金額)。另一個較為複雜的則是不易定義範疇的分析,其分析模式與工具也尚在開發中。畢竟,要”知道”哪些”自己不知道”的,原本就是非常困難。 不論是指導步驟或是擷取、組織與分析步驟的目的均是要能決策,因此指導是否有意義,分析結果是否能產生價值,其最終的判斷準則均要能用於決策。以現有海量資料分析方法論中,均集中在擷取、組織與分析步驟,其實真正關鍵的是決策與組織。決策與組織步驟的好壞影響了海量資料分析價值的八成結果。 資料分析的價值與應用 資料分析的應用簡單來說可以從Google的搜尋紀錄能掌握流感傳染的即時狀況、從顧客購買的物件分析,能推測顧客的個人狀況(例如已經懷孕)、從天候及機場航程資料,能預測機票價格的變化、從手機訊號的聚集,能查知交通的狀況或是從住房相關資料的分析,能篩選出高火災危險的住宅等等。 以最近被NAVER併購的Gogolook團隊的例子來做說明,台灣新創公司Gogolook的主力產品為來電辨識與號碼管理服務 whoscall,當電話響起時,whoscall 能即時顯示來電者的身分,並警示該來電可能是行銷電話、騷擾電話,也能過濾掉拒接的來電。而這種來電辨識功能是藉由網路上的即時搜尋以及其APP底下用戶的回報所建立而成,因此若網路上搜尋不到或是沒有用戶回報就會造成無法判斷該通來電可能的身分以及是否為惡意電話,為了改善這個困境,他們利用當時whoscall的底下400萬用戶,每天約1000萬通通話的資料量,來進行資料分析,進而建立惡意電話以及詐騙電話所擁有的行為模式,透過分析這些惡意及詐騙電話的發話頻率、發話對象、鈴響時間、通話模式,也就是「Call Pattern」,根據他們的研究,一般正常使用的電話,每天發話、接電話的頻率大概是 1 至 2 通,且通常有特定通話對象;行銷電話每天發話的頻率在 10 通以上、發話相隔時間短、對象都不相同,且僅限於周一到周五電話行銷專員有上班的日子才有發話紀錄,至於少有的來電則被判讀為受話端因為漏接而回撥的來電。 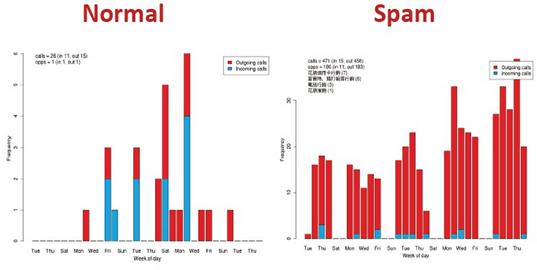 《圖三》 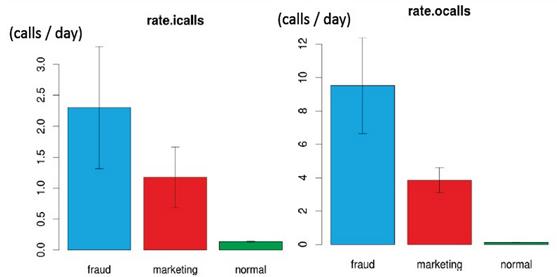 《圖四》 此外,一般正常使用的電話,每通電話平均的通話時數約在 1 分 12 秒;但詐騙電話(Fraud Numbers)的平均通話時數 30 秒不到,行銷電話(Marketing Numbers)的平均通話時數 36 秒不到,顯然是被接起之後立刻就被掛斷。 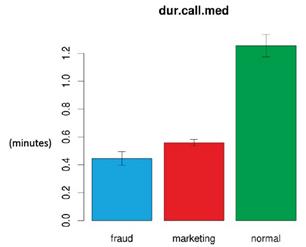 《圖五》 而找出 Call Pattern 之後,whoscall 在一通電話之間判斷其是否為惡意電話的準確度高達 93%,在兩通電話後,判斷的準確率則提升至 96%。在現代人電話不離身、卻又飽受行銷電話搜擾的情況下就因為如此精準的惡意電話辨識,whoscall 能在各家來電辯識服務中建立了不可取代性,也使得其商業價值因此大幅提升。 結語 順著BigData的潮流,資料分析也成為越來越熱門的技術,相對的資料的蒐集與保護也是一個值得注意的議題,每一天,每個人在臉書所有的留言、打卡或按讚被蒐集在各企業的伺服器上;每個人的容貌和打扮都被安裝路口及大賣場的監視器捕捉並記錄;每個人何時何地刷卡買了什麼東西,都被發卡銀行分類歸檔。 在大數據時代,每個人在不知不覺中「被蒐集」,再加以資料整合與加總。或許有人不在意,但對於隱私至上的信奉者而言,等於是一種「數據監控」,而當龐大數位資訊碰上個資法,資料管理以及資料外洩防護也變成提升企業競爭力的關注重點。相對地,出問題的原因,並不見得是在數據量,而是因為平台變多讓資料外洩的問題增加許多,對一般企業來說,以前資料就只是擺在公司裡,但,現在不一樣,資料都放在外部,怎麼備份、怎麼保存在不同的平台,還要防止Data Loss(資料外洩),將這些事情交錯來看,都將使得企業面臨更多挑戰。若因資料外洩而讓公司名字見報,不光是罰款的問題,還牽涉到企業名譽,甚至進一步影響它在所屬產業中的市場地位,這些可能都會帶來很大的負面影響。 參考資料 1.海量資料分析 2.Gogolook 怎麼快速累積新台幣 5.29 億的價值? 3.海量資料(Big Data)分析五部曲
|

|
凌群電子報/一九八四年五月二十日創刊 |