
第343期 / May 5, 2026 |
演算法到模型的解密:機器是如何「懂」人話的?作者/陳冠豪 [發表日期:2026/5/5] 作者簡介 作者目前擔任凌群電腦資通技術處經理,現專職AI解決方案規劃與領導AI專案開發,並規劃凌群AI開發團隊之研究方向。 從觀念重塑到技術前線:AI 開發的下一步 在先前的三篇專欄中,筆者著重在AI應用開發的觀念與重塑,我們首先探討了傳統的軟體開發和AI開發邏輯的不同之處,也因此AI的應用開發需要研究團隊,而這研究團隊的「資料工程」如何為 AI 打造穩定的技術供應鏈;當這些海量且乾淨的資料被送進 AI 的黑盒子後,那麼它到底是如何「讀懂」這些資料,甚至能像人類一樣對答如流的呢? 很多人以為 AI 像人類一樣在「閱讀」文字或「觀看」圖片,但事實上,這是一個對AI最大的誤會;今天開始專欄將正式進入技術拆解的階段,我們首先就來拆解這個黑盒子,看看演算法究竟在做什麼。 機器眼中的世界:一切皆為數字 當我們專注看著前方,並駕駛車輛行駛時,我們看到的是馬路、行人和前方的車輛,但對於電腦來說,「模型看到的究竟是什麼?」。 答案是:網格與座標,在機器的眼裡,並沒有「車子」這個概念,它知道的只有一堆像素點與數值,而它所看到的則是像「N 25°03′53.4」這樣的座標位置,以及被切割成無數網格方塊後所代表的數值(如 10、74、12 等)。 這就是AI理解世界的第一步:將現實世界的一切(影像、聲音、文字)全部轉換為數字矩陣(就如同電腦只看得懂0和1是一樣的)。 模型就是演算法:一場大型的數學運算與統計 既然世界變成了數字,那模型又是如何做出判斷的? 大家可以把演算法想像成一個具有無數關卡的「數學過濾網」,當感測器捕捉到的數字進入這個過濾網後,會開始執行一連串我們在國小都學過的數學運算:
最後,演算法會根據總和的結果來觸發指令。例如:
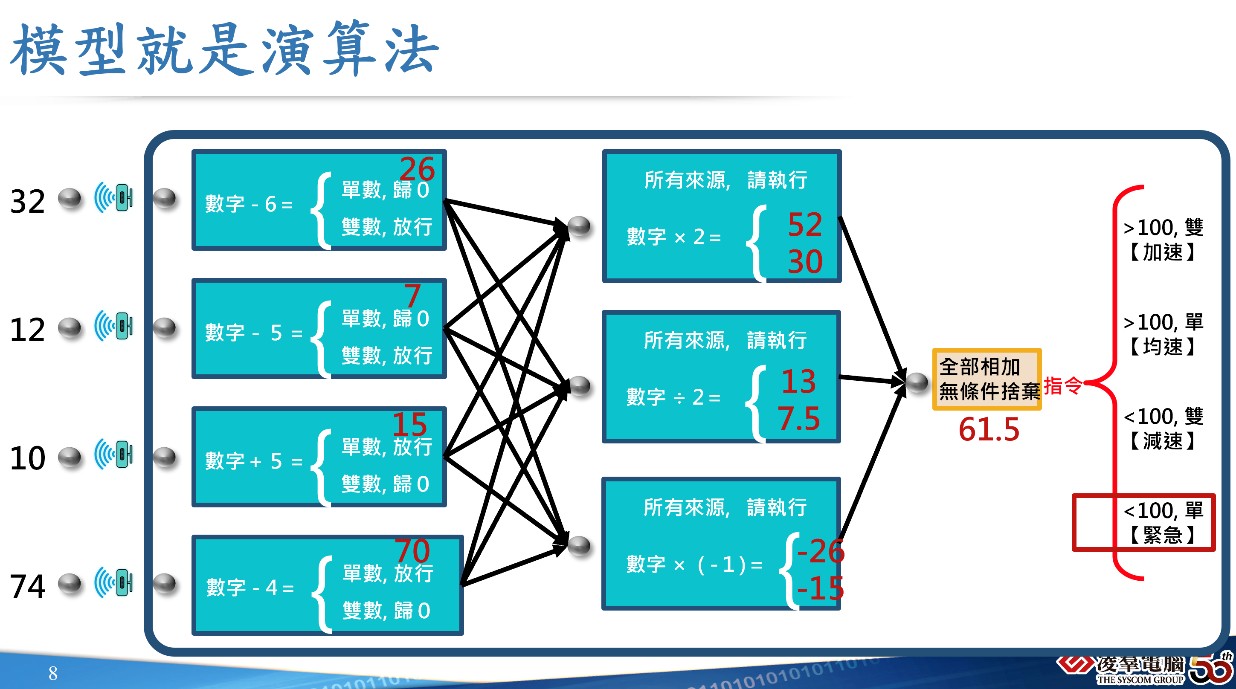 《圖說》圖片來源:筆者自製 以上就是實際上模型在做的事情,而依據不同的規則(權重),就會產生出「演算法的好壞差異」;一個優秀的演算法,其內部的數學權重分配得非常之精準,能做出正確的數值判斷,避免模型自身的泛化與擬合問題發生不精準的狀況。 從線性邏輯到「人工神經網路」 然而,人腦的運算真的太複雜了,如果只是單純判斷前方有沒有車,傳統的加減乘除或許還能應付;但如果我們要機器去辨識貓的品種,或是理解一句充滿反諷的中文,傳統的演算法就會崩潰,這時,我們就需要「人工神經網路」。 它不再只是單向的流程圖,而是模擬人類大腦神經元,交織成一個錯綜複雜的立體網狀結構,在神經網路的隱藏層中,每個節點都在進行極其複雜的特徵提取與權重計算,例如運用神經元輸入的加權總合> 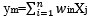 這類公式來處理數據;這種運算其實已經超越了人類能夠手動撰寫規則的極限,因此我們則讓機器自己從海量數據中「訓練」出這些權重。 這類公式來處理數據;這種運算其實已經超越了人類能夠手動撰寫規則的極限,因此我們則讓機器自己從海量數據中「訓練」出這些權重。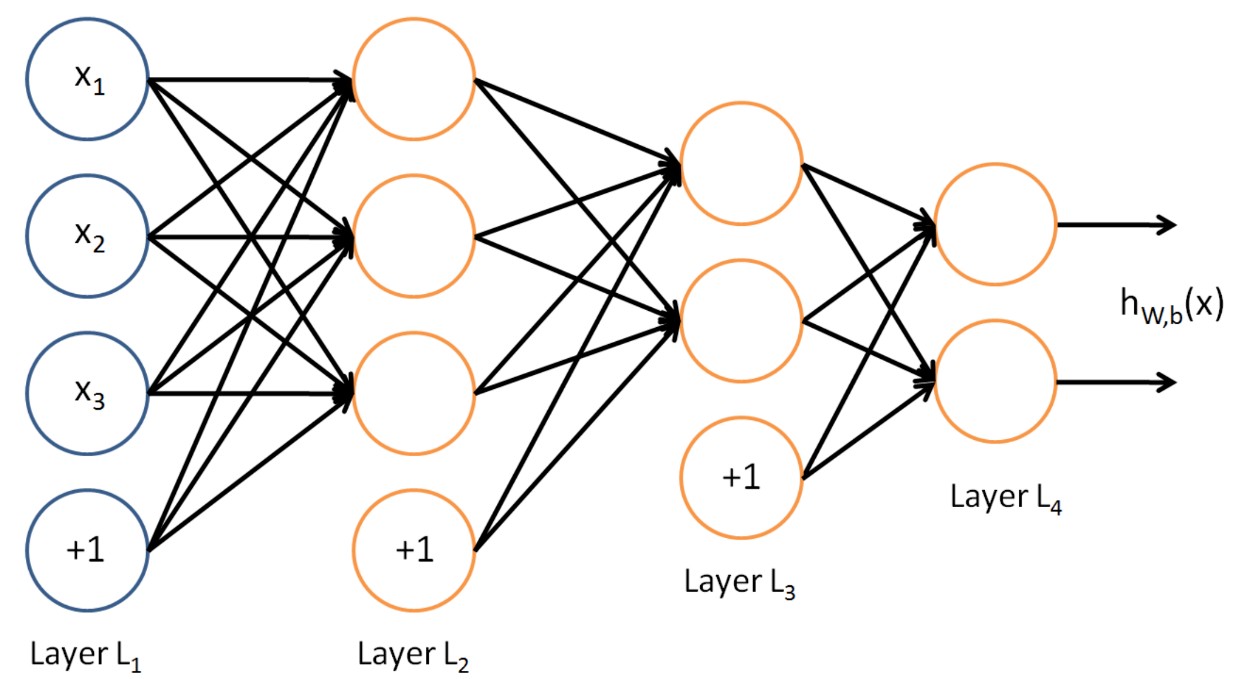 《圖說》《深度人工神經網路示意圖》圖片來源:Stanford Deep Learning Lab 人類 VS 人工智慧:它真的「懂」你嗎? 上述的概念或許很抽象,我們最後的總結只要去「人類 VS 人工智慧」,就會簡單許多。 對於現代的 AI 系統(如自駕車或語音助理)來說:
這正是近幾年引爆全球熱潮的大型語言模型(LLM),例如 ChatGPT 或 deepseek 的運作本質,所以當我們在對話框輸入「請幫我寫一封道歉信」時,它並不會感受到我們的愧疚,也不會理解「道歉」的情感是什麼,它所做的,是將句子轉換成數萬個向量座標,然後用天文數字等級的「人工神經網路」 去計算:在這個情境下,下一個最應該出現的「字(Token)」的機率是多少。 模型其實從未真正「懂」過人話,它只是把數學算到了極致,極致到看起來就像是懂了一樣。 既然我們知道 AI 本質上是一台超大型的「機率計算機」,那麼我們身為使用者,該如何給定正確的變數,讓它算出我們想要的好答案? 這就帶出了下一期的主題:與這台計算機溝通的新學問——「Prompt Engineering:與 AI 溝通的新學問」。
|

|
凌群電子報/一九八四年五月二十日創刊 |