【第156期 September 5, 2010】 |
||
研發新視界[發表日期:2010/8/23]
 《圖一》 於是可以很輕鬆的得知,書中的哪幾頁有包含「電腦」這個關鍵字。藉由索引的幫助,我們把這項可能會耗去好幾年寶貴青春的無趣作業,縮短到在幾秒鐘之內完成。當我們要搜尋的對象是資料庫時,情形也是類似的,讀遍百科全書的每一頁的方法,在資料庫裡就相當於使用 like ‘%keyword%’ 這種方法又稱為「順序掃描法(Serial Scanning)」。所謂順序掃瞄,就是當我們要找內容包含某一個關鍵字的文件時,就一個文件一個文件的看,對於每一個文件,從頭看到尾,如果此文件包含這個關鍵字,那麼它就是我們要找的,接著看下一個文件,直到掃瞄完所有的文件。 雖然這種方法比較原始,但對於小量的文件,這種方法還是最直接,最方便的。但是對於大量的文件,這種方法就很慢了。「like」對性能的危害是極大的。如果是需要對多個關鍵詞進行查詢而使用 like’%keyword1%’ and like ‘%keyword2%’... 其效率絕對是無法忍受的。 而索引可以看成是一種「反向表格」,也就是相對於把書本內容當成是有「頁數=>一堆關鍵字(即文章)」如此對應關係的正向表格,索引裡記錄的是「關鍵字=>一堆頁數」這樣的顛倒的對應關係。於是當我們要查找某個關鍵字時,利用索引結構的便能立即告訴我們需要的文件在什麼地方。 但索引也並不是無中生有來的,在使用索引之前,我們必須對資料進行建立索引的動作,也就是由正向表格建立出反向表格的過程,具體來說就是依序去把每一筆資料從頭讀到尾,要是看到了認為可以算是關鍵字的詞語,就去檢查看看現有的索引表裏有沒有這個詞語,要是有,就把資料的編號註記在相對應的位子,沒有的話,就把這個詞語跟文件編號新增到索引表。而這個過程也絕不輕鬆,更別提之後的排序及維護的成本。 利用索引的確加快了搜索的速度,但是多了建立索引的過程,兩者所花費的時間加起來不見得比順序掃瞄快多少,尤其是在資料量小的時候更是如此。而且對大量的資料創建索引也是一個很漫長的過程。 即使如此,建立索引還是很划得來的,因為索引可以一口氣列出所有關鍵字與資料的對應關係,也就是「窮舉」了未來使用者有可能下的所有查詢字,這樣的過程只需要一次並將結果加以保存,以後便是一勞永逸的了。每次搜索不必再次經過建立索引的過程,只要直接搜索先前建立的索引就可以了。而順序掃瞄法是則每次查詢都要耗費同樣的時間掃瞄全部文件。這就是全文檢索相對於順序掃瞄的最大優勢:一次索引,多次使用。 像這樣先建立索引,再對索引進行搜索的過程就叫全文檢索(Full-text Search)。 Lucene Lucene是一個免費的Java全文檢索函式庫,將其引入到程式中,便能簡單的打造出自己的搜尋引擎來。 Lucene的作者Doug Cutting是一位資深全文檢索專家,曾經是V-Twin搜索引擎(Apple的Copland操作系統的成就之一)的主要開發者,後在Excite擔任高級系統架構設計師,目前從事於一些網路底層架構的研究。他貢獻出的Lucene的目標是為各種中小型應用程序加入全文檢索功能。 作者最初發佈在自己的www.lucene.com,後來發佈在SourceForge,2001年底成為APACHE基金會jakarta的一個子項目:http://jakarta.apache.org/lucene/ 由於 Lucene 提供了簡單易用的 API,所以即使對進行索引的機制並不太瞭解,也可以非常容易的使用Lucene實現對資料的索引。 以下我們使用Lucene,搭配Java與MySQL製作一個簡單的新聞查詢器。 一開始建立如下的表格,用來存放新聞資料: 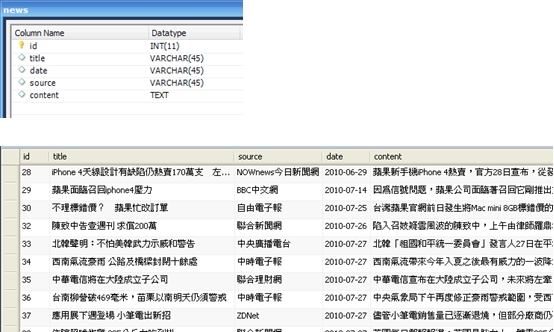 《圖二》 一、建立索引 製作索引時主要會使用到的類別是Analyzer與IndexWriter。 Analyzer的功能是用來分析文件,並決定在文件內容中的哪些詞語要被當成關鍵字。就像我們在查找書本索引時,也可能會發生索引的關鍵字表中,並沒有我們要查的字在其中的情形。索引中關鍵字表要放些什麼內容,就是由Analyzer來負責。 而IndexWriter就是負責將索引寫入到檔案的東西。使用的方式如下:  《圖三》 在這裡我們使用StandardAnalyzer,較新版本的StandardAnalyzer已支援對中文文件的分析。 Lucene建立索引的過程中,是將一筆筆的Document物件寫入到索引檔裡。這也是Lucene的一大優點:不需要在乎資料來源的格式,只統一提供了Document的介面,對於不同種類的來源(資料庫、網頁、PDF…),只要使用相對應的轉換器轉換成Document格式就行了。 Document物件中存放的是經過處理後的資料欄位,這些欄位分為兩種:(1)用來製作索引的欄位(2)顯示給使用者看的欄位。 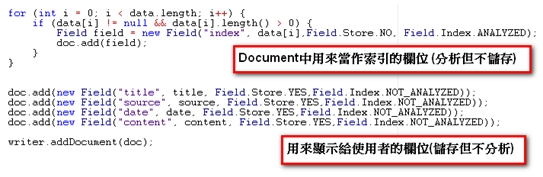 《圖四》 到此我們便完成了建立索引的大致流程。 執行結果: 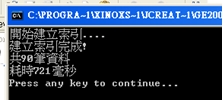 《圖五》 在指定的位置會產生如下的索引檔:  《圖六》 二、搜尋資料 搜尋資料時主要會用到的類別是QueryParser與IndexSearcher。 首先由QueryParser來對使用者所下的條件進行解析,解析完成產生的Query便交由IndexSearcher來進行對索引的搜尋。 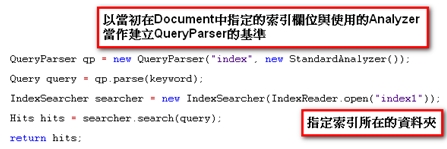 《圖七》 搜尋到的Document資料存放在Hits物件中,與用於資料庫的ResultSet類似,可利用迴圈與doc()方法走訪,再用get()方法取出欄位。  《圖八》 最後再利用Swing製作簡單的介面,完成的模樣如下:  《圖九》 交集:  《圖十》 聯集: 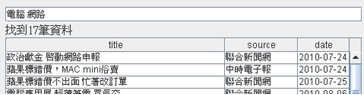 《圖十一》 差集: 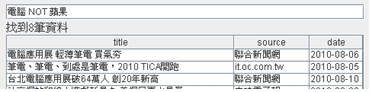 《圖十二》 藉由Lucene這套方便的工具庫,我們可以在幾乎完全不用碰觸索引建立機制的情形下(事實上我們所做的,就只有在程式碼裡寫下「幫我做索引!」跟「幫我查資料!」而已),便能夠完成一個堪用的全文檢索系統。 而Lucene也有著良好的物件導向特性,當以Lucane製作全文檢索系統時所使用到的各個類別,幾乎都可以獨立的將其零件化拆解出來,再由我們自行加以擴充或者是改變。 例如在這個例子中我們直接使用了內建的StandardAnalyzer,但也總是會有分析器預設的文件分析方式不足以應付我們的需求的情形。 這時我們可以對分析器進行修改,一個Analyzer其實就是好幾個TokenFilter拼裝起來的,每個TokenFilter代表的是一個語句的分析策略,一堆TokenFilter組成一整套的分析策略就成了Analyzer,所以當Analyzer的分析方式不符我們的需求時,只需要自行撰寫TokenFilter再附加在Analyzer上即可。而寫好的TokenFilter,日後還可以提供給其它不同Analyzer使用,達到重用(reuse)的效果。 參考資料 http://lucene.apache.org/ http://www.chedong.com/tech/lucene.html http://catyku.pixnet.net/blog/post/22844946 http://forfuture1978.javaeye.com/blog/546771 http://hi.baidu.com/lewutian/blog/item/15049eb369022dabd9335aec.html
|
 友善列印
友善列印 轉寄友人
轉寄友人