【第178期 July 5, 2012】 |
||
研發新視界[發表日期:2012/7/5] 前言  《圖1、Hadoop的Logo》 Hadoop的計算部分是採用MapReduce,而底層的檔案系統也是採用GFS的概念,但是名稱改為Hadoop Distributed File System,簡稱HDFS。Hadoop的MapReduce與HDFS在下兩節會詳細介紹。 由於Hadoop架構非常的穩定,因此採用此架構的應用相當多。其中Yahoo是最大的贊助者,也是使用最多的業者。根據Yahoo所公布的訊息,在2008年2月時Yahoo就已經建立全球最大的Hadoop應用架構,將其應用在Webmap的建立之上,而Webmap專案其實就是Yahoo Search的核心搜尋計畫。詳細資料如表1。  《表1、Hadoop應用於Webmap》 依據Yahoo在2008年9月所公布的Hadoop架構平台,不僅處理能力相當驚人,HDFS檔案系統的資料儲存能力也達到了16PB,這是一般的檔案系統難以達成的目標。詳細資料如表2。 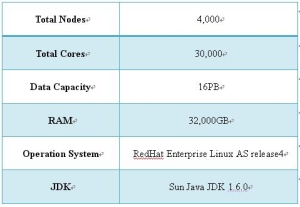 《表2、Yahoo擴大Hadoop架構》 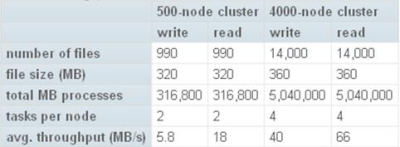 《圖2、500-nodes vs. 4000-nodes throughput》 從圖2可以看出當Hadoop的node數從500增加到了4,000,不僅處理的檔案數大幅增加,4,000-node的寫入的throughput增加為原來的將近7倍,而讀取也是原來的3.6倍。並且每個節點所能處理的任務數也由原來的2個增加到4個。 HDFS的設計目標
在HDFS的系統中,硬體的錯誤應該要被視為正常的情況,也就是說常常會發生。因為HDFS檔案系統是由數百或是數千個機器所組成,而每台機器都存放一部分的檔案系統資料。所以檔案系統不能因為某個機器發生錯誤,就無法提供服務。因此HDFS必須要將錯誤偵測與快速且自動地恢復系統錯誤視為系統的核心架構服務。 必須要提供透過HDFS存取資料的應用程式串流式的資料存取,因為該資料量通常是非常的龐大。並且HDFS應設計成適合批次處理的應用,而不是用在即時的使用者回應。所以高傳輸量的資料存取是比存取資料的低反應時間,還要來的重要。 儲存在HDFS的資料量通常都非常龐大,一般來說檔案大小從數GB到數TB都是很常見的大小。因此單一大檔可能需要被分割成數以千萬計個小檔案,而且HDFS要能正確地控管這些小檔案。 HDFS上的檔案通常都是屬於”一次寫入,多次讀取”的模型,也就是說,當檔案一旦建立、寫入、關閉之後通常就不會再修改了。這樣的模型簡化了資料多次寫入後副本間需一致性的困擾,所以才能有比較高的資料傳輸量。 由於儲存在HDFS檔案系統的資料通常都非常的龐大,因此通常是不會存放在單一機器上。而若是要將存放於各部機器上的資料移到某一台上執行,這會浪費許多的資源,所以不如將計算的功能移到各個存放資料的機器上,就地運算。那麼資料也就不需要移動了。 HDFS的設計應該要能輕易地從一個平台移植到另外一個平台。這樣的特性將使得很多的系統都能夠採用HDFS為其檔案系統。 Namenode與Datanode HDFS是一種主從式架構的檔案系統,因此一個大的HDFS叢集會有一個master當作Namenode,而其他的機器則是當作Datanode。 Namenode主要是管理檔案系統的命名空間、管理檔案存取的權限或是一個大檔被分割成幾個小檔並且儲存在哪些Datanode上等等稱之為Metadata的資料。所以Namenode實際上並不存放資料,但是當使用者需要存取檔案時第一步都是要先和Namenode連線已取得檔案的實際位置,如此一來也降低了Namenode變成HDFS的效能瓶頸的可能性。 Datanode則是資料實際存放的地方,Datanode除了會執行Namenode所要求的指令外,還需要應付使用者對資料的讀取與寫入,因為檔案會被分割成多個,並且存放在多台不同的機器上,因此可以加快資料的讀取速度。但是對於寫入則會因為資料副本的關係,而有所延誤。如下圖。 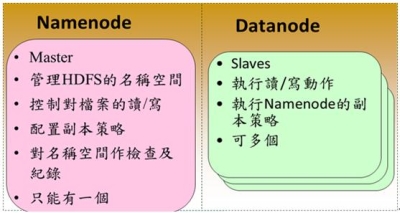 《圖3、Namenode與Datanode的工作分配》 通常Namenode與Datanode都是運行在一般的機器上,並且執行Linux的作業系統。但是由於HDFS是使用Java所開發,所以任何支援Java的機器都可以運行Namenode與Datanode,並沒有限定在Linux上。 圖4是HDFS的系統架構圖。從圖中可以看到Client在讀取資料前,須先與Namenode連線以取得檔案實際上所存放的位置,之後再向存放資料的Datanode做出讀取的動作,若該檔案比較大也有可能檔案會被存放在多台的Datanode中,那麼Client就可以同時對多台Datanode發出讀取的動作,以加快資料的讀取。 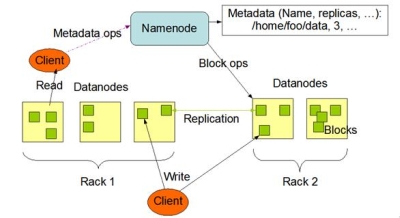 《圖4、HDFS的架構》 資料的複製 HDFS主要是用來存放大規模的資料集,因此系統預設單一檔案若是超過64MB則會被分割成多個一樣大小的區塊(block)。而這些區塊為了提供容錯的機制,因此必須要有副本的策略,也就是說單一區塊會被複製到多台Datanode中存放。系統預設的副本數是3,但是副本數可以由使用者建立檔案時或是之後來做調整。 如圖所示,Namenode所控制所有區塊的複製動作。它會周期性的收到來自各台Datanode的Heatbeat與Blockreport。Heatbeat是表示該Datanode還在正常的運行中,而Blockreport則是列出該Datanode上的所有區塊檔案。 例如下圖中的myFile檔案的副本數為2,區塊為1號與3號,從圖中可以看到1號區塊存放在D1與D3的Datanode中,而3號則是存放在D5與D7的Datanode中。 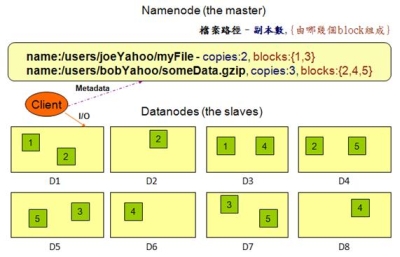 《圖5、資料的複製模式1》 假設D7的Datanode機器掛掉了,那麼存放在D7上的3號與5號資料就會遺失。這時HDFS的Namenode就會發現3號區塊的副本數不足2個,5號區塊的副本數不足3個。因此就會找出區塊數比較少的Datanode,將其他機器上的3號與5號區塊各自複製過去,以達到所設定的最低副本數。如下圖。 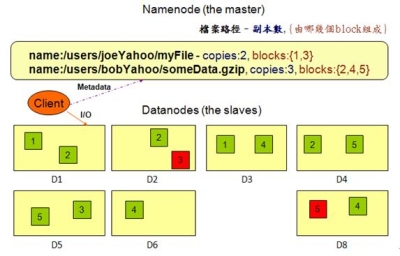 《圖6、資料的複製模式2》 Hadoop的MapReduce撰寫模式 MapReduce其實就是一種Divide與Conquer的過程,適當地將問題Divide出來,並且透過Map的機制在各個機器上平行執行,最後再將Map產生的結果Reduce起來(根據某一個Key),以得到最終的結果。 Hadoop中的MapReduce是一個實作Google的MapReduce的分散式運算架構,基於Hadoop所撰寫出來的應用程式能夠在上千台的機器上同時執行,並且藉由Hadoop平台所提供的容錯機制,開發人員可以完全不需要理會當任務失敗時所產生的錯誤,因為該平台會自動地將發生錯誤的任務重新分配給其他的機器來執行。 如下圖。一個MapReduce工作(job)通常會把需要處理的資料分割成各自獨立的區塊,由map任務(task)以平行的方式於各台機器中處理。Hadoop會對map的輸出資料先進行排序,然後再把結果當作reduce任務的的輸入資料,進行處理。因此有幾個reduce任務就會有幾個輸出結果。而不論是輸入或是輸出的資料,都是存放在Hadoop的HDFS檔案系統內。 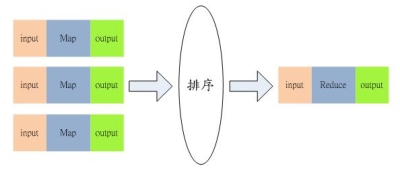 《圖7、MapReduce的輸入輸出模式》 MapReduce架構由一個獨立的master機器與多個slave機器所組成。master又稱之Jobtracker,主要負責執行開發人員所要執行的工作,當Jobtracker接收到此工作(job)時,會將此工作分成好幾個任務(task)交由底下的slave機器去執行。因此JobTracker本身並不會真正的去執行Map與Reduce程式,而是負責監控各個任務的執行狀態,假若有某台slave機器掛了,則Jobtracker就必須負責將該機器上的任務重新分配給其他的slave處理。而slave又可稱之為Tasktracker,僅負責執行Jobtracker所交辦下來的任務,當任務執行完畢後再回報給Jobtracker。Jobtracker與Tasktracker的工作分配可參考下圖。 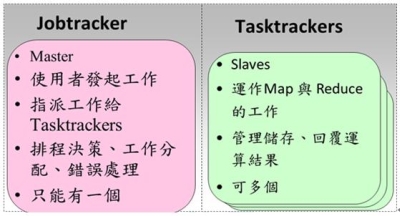 《圖8、JobTracker與TaskTracker的工作分配》 開發人員撰寫程式時,一般都會指定程式資料在HDFS的輸入與輸出路徑。也會設定真正執行Map與Reduce的程式名稱。再加上其他的作業參數,就組成了工作配置(Job Configuration)。之後,Hadoop的job client再送出包含程式的jar檔與工作配置給Jobtracker,Jobtracker就會負責將程式與工作配置資訊送給slave,並且監控他們的執行狀況。 執行流程介紹 1.開發人員透過命令列指令送出含有MapReduce程式的jar檔給JobClient。 2.InputFormat負責做Map的前處理,主要包含下列幾項工作:
3.將RecordReader處理後的資訊做為Map的輸入資料。然後執行開發人員所定義的程式,執行完畢後再產生key/value pair的資料。 4.Combiner是選擇性的動作。主要的作用是在每一個Map執行完畢後,先在本機端作Reduce的動作,用以減少在後續Reduce過程中的資料傳輸量。 5.Partitioner也是選擇性的動作。主要是在多個Reduce任務的情況下,指定某Map的執行結果要由特定的Reduce處理。 6.Reduce階段則是將上階段傳過來的資料,進行簡化的動作。因此會去執行開發人員所定義的程式,並且將處理的結果輸出給OutputFormat,而每一個Reduce任務就只會產生一個輸出檔。 7.OutputFormat主要提供下列作用:
8.MapReduce程式執行完畢。 結語 現行具有社群功能的系統已經相當普遍,大量社交行為所產生的資料量相當的龐大,不僅需要龐大的儲存空間,其複雜度更是需要消耗許多運算時間才能得到結果。當然不僅僅是只有社交系統才會產生如此多的資料,其他像是銀行的交易資料或是遊戲系統產生的玩家行為資料等等,都會產生大量資料。如此可見雲端資料庫的重要性也將與日俱增,相信未來雲端資料庫的使用會越來越普遍。而Hadoop的OpenSource架構則是提供給企業除了商業解決方案外更容易客製化的選擇。 參考資料 [1]Amazon Elastic Compute Cloud,http://aws.amazon.com/ec2 [2]Amazon EC2 Instance Types,http://aws.amazon.com/ec2/instance-types/ [3]Applications powered by Hadoop:http://wiki.apache.org/hadoop/PoweredBy [4]Dean, J., and Ghemawat, S., 2008, “MapReduce: Simplified Data Processing on Large Clusters”, Communications of the ACM, 51(1): p. 107-113. [5]Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E. Gruber, 2006, “Bigtable: A Distributed Storage System for Structured Data”, 7th USENIX Symposium on Operating Systems Design and Implementation, pp.205-218. [6]Hadoop,http://hadoop.apache.org/ [7]Nutch,http://nutch.apache.org/ [8]Sanjay, Hgobioff, and Shuntak, 2003, “The Google File System”, 19th ACM Symposium on Operating Systems Principles(SOSP). [9]Scaling Hadoop to 4000 nodes at Yahoo!,http://developer.yahoo.net/blogs/hadoop/2008/09/scaling_hadoop_to_4000_nodes_a.html [10]Shadi Ibrahim, Hai Jin, Bin Cheng, Haijun Cao, Song Wu, 2009, “CLOUDLET: Towards MapReduce Implementation on Virtual Machines”, Proceedings of the 18th ACM international symposium on High performance distributed computing, Pages: 65-66. [11]Shadi Ibrahim, Hai Jin, Lu Lu, Li Qi, Song Wu, and Xuanhua Shi, 2009, “Evaluating MapReduce on Virtual Machines: The Hadoop Case”, Proceedings of the 1st International Conference on Cloud Computing, Pages: 519 - 528. [12]Spears, W. M., De Jong, K. A., Back, T., Fogel, D. B., and deGaris, H., 1993, "An overview of evolutionary computation", Proceedings of the 1993 European Conference on Machine Learning. [13]Welcome to NCHC Cloud Computing Research Group,http://trac.nchc.org.tw/cloud [14]Yahoo! Launches World's Largest Hadoop Production Application,http://developer.yahoo.net/blogs/hadoop/2008/02/yahoo-worlds-largest-production-hadoop.html
|
 友善列印
友善列印 轉寄友人
轉寄友人