【第169期 October 5, 2011】 |
||
研發新視界[發表日期:2011/10/3] 前言
關聯式資料庫具有支援非常複雜的資料表結構、利用SQL語言作出各式各樣的查詢,以及維持資料庫的資料一致性等特性,但等價交換下,關聯式資料庫每次的Transaction所花費的計算是相當大的,特別是如果每秒都有上千次,甚至上萬次對關聯式資料庫進行讀寫,就會讓整個資料庫負荷相當沈重。因此各大型網站都必須設計非常多層的快取、Replication等機制,來減輕、分散他們資料庫的負擔,傳統關聯式資料庫已經成為許多網站系統的擴充能力重要瓶頸。 Huge Storage 知名美國社交網站Friendfeed,每個月可以產生2.5億條的用戶動態訊息,對關聯式資料庫來說,查詢一張擁有2.5億條紀錄的資料表,是極沒有效率且無法忍受的,因此大量儲存需求問題也是傳統關聯式資料庫所面對的難題之一。 High Scalability & High Availability 一般來說,關聯式資料庫是相當難以進行橫向擴充的,往往必須進行停機來進行資料庫的擴充及轉移,無法動態進行資料庫新增節點和負載平衡的工作。 NoSQL資料庫並非是近年來的產物,但在上述三種需求下,NoSQL又再度從歷史的洪流中受到矚目。NoSQL資料庫其實是多種非使用Sql語法查詢的資料庫總稱,大致可以分為下列幾類。
存放Key/Value成對的簡單構造。分散Cache的memcached以及Amazon.com的Amazon Dynamo採用的資料模式。 列指向的表形式型 具有能夠處理列方向的構造。像美國Google的BigTable、由Facebookn所發展的Cassandra等。 文件指向型 轉換成XML、JSON等文件形式保存方式。像美國10gen公司的MongoDB,Apache的CouchDB等。 在此將針對Cassandra來進行較深入的介紹。Cassandra最初由Facebook開發,之後Facebook讓Cassandra成為開放原始碼的Apache專案之一,由於Cassandra良好的可擴放性,被Digg、Twitter等知名Web 2.0網站所採納,成為了一種流行的分布式結構化數據存儲方案。 Cassandra的資料模型 Cassandra的資料模型如下,它可以被視為是一個四至五維Hash Table,從上到下,層次結構如下圖所示。 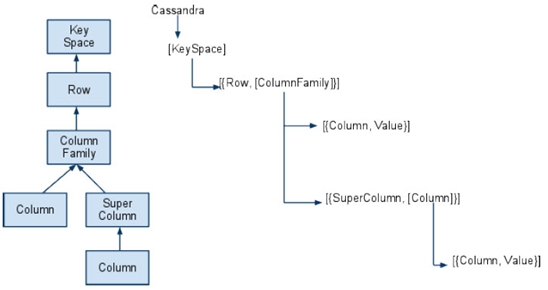 《圖一》 Key Space 在 Cassandra,你可以定義多個 key space。 它就像是 MySQL 裡面的table。 它是一個(Row,[ColumnFamily])的list。 通常每一個應用可以對應到一個 key space。 Row 對於 row key,你對每個相對應的 column family 都可以儲存資料。 在每一個 column family 資料中是根據 row key 來做排序。 Column Family 在 column family,它包含一個 column list 或 super column list。 每一個 column family 都儲存在一個單獨的文件。 而每一個 column family 都可以存無限多個 column。 Super Column Super column 是一個包含著許多 column 的 list。 Column 它是最小的元素資料,它僅包含一個 name,一個 value,和一個timestamp。 您可以在任何時候添加新的或刪除 column。 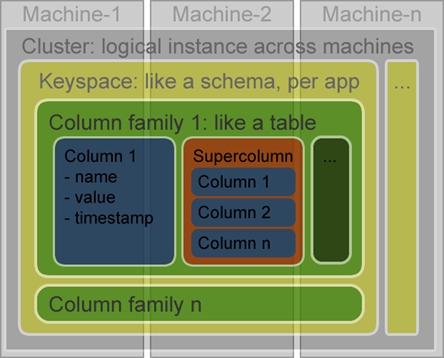 《圖二》 上圖為Cassandra的整體架構示意圖,Keyspace就像是整個資料庫,將資料擴散在各個machine(node)中,這些node形成一個cluster,cluster可以動態無限新增node,因此解決了傳統資料庫無法動態擴充節點的問題。 Cassandra 使用 consistent hash 來做 key partition。 每個節點在Cassandra cluster 中將在 ring 中選取一個 token(0 下面的例子為insert一筆新的key時,key 將被插入到節點 2 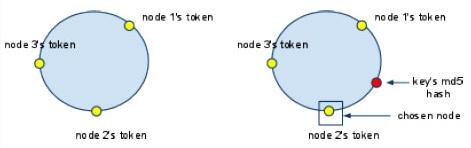 《圖三》 如果你想儲存兩個副本的資料在 Cassandra cluster。 它將資料存儲在hash值後的兩個節點中。如以下圖所示。 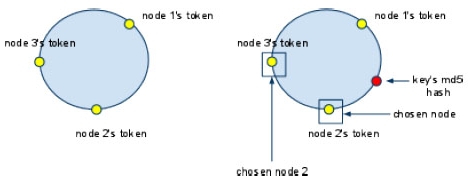 《圖四》 在Consistent hash,添加一個新節點只會影響鄰居節點。在這種情況下,我們並不需要重新分配所有資料。以下圖為例,一些資料存儲在節點 1 現在將存儲在新的節點4,新的節點將隨機選擇一個 token,並根據 MD5 找到相應的位置。因此,我們要在Cassandra cluster中新增一個節點是相當容易的,不需要完全動到整體的架構即可達到擴充性的目的。 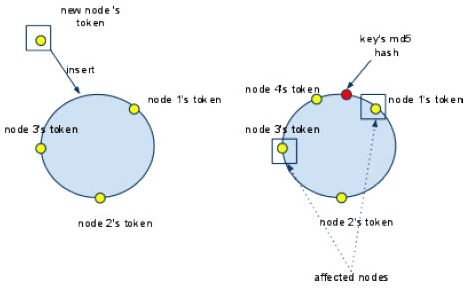 《圖五》 參考資料來源 網頁 http://www.cellopoint.com/tw/media_resources/blog/2010/06/cassandra-data-model http://wiki.cheyingwu.tw/Java/Cassandra/DataModel http://en.wikipedia.org/wiki/Apache_Cassandra http://en.wikipedia.org/wiki/Apache_Cassandra http://www.ithome.com.tw/itadm/article.php?c=63360 文件 Bigtable: A Distributed Storage System for Structured Data - Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber
|
 友善列印
友善列印 轉寄友人
轉寄友人