人工智慧之幕後功臣-『深度學習』
作者/李凱平
前言
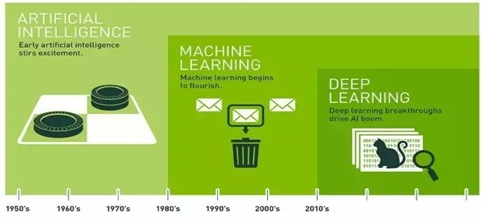
許多科幻電影中的機器人,往往是我們對人工智慧想像的產物。1999年一部電影《變人》開啟了人們對服務機器人的需求,2004年又一部電影《機械公敵》讓我們了解到機器人反撲的可怕,後續有許多電影讓我們預想到人工智慧後的新世界,感受到人工智慧的強大。直到2016年南韓圍棋選手被AlphaGo打敗後,人工智慧的討論度在網上又是一陣熱潮,機器學習、深度學習等技術攻佔了各大社群及媒體版面,本文接下來將討論,是什麼技術讓人工智慧躍了一大步?
大數據後的推手 - 機器學習
機器學習(Machine Learning)是人工智慧發展中很重要的一環,指的是讓機器透過歷史資料,「自主」並「增強」所使用的演算法,透過不同的演算法所建構出預測模型,預測所關心議題的結果,並根據結果的準確度持續調整模型,使之達到更高的精準度。而機器學習的應用早已遍布我們的生活當中,像是熟悉的垃圾信件功能、喜好推薦系統、停車場車牌辨識、語音辨識及臉部辨識等等,在商業用途上,可讓消費者得到專屬的服務,或是讓決策者可以根據預測結果,提早做出判斷,得以減少損失或是創造更高的利潤。
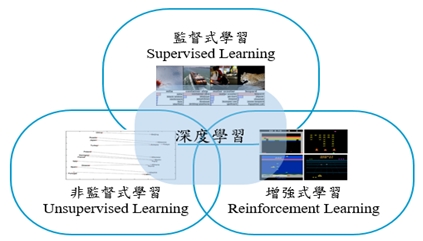
《圖一》
因學習風格及方式不同,機器學習種類主要分為三類,分別為「監督式學習(Supervised Learning )」、「非監督式學習(Unsupervised Learning)」、「增強式學習(Reinforcement Learning)」,說明如下:
一、監督式學習:
給定的訓練資料(Training Data)需有資料特徵及明確標籤以建構預測模型,當新的特徵值進入模型時,得以判斷預測結果。像是給定一張圖片,程式可判斷為何種項目。
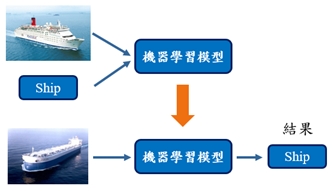
《圖二》
訓練資料沒有進行標註,利用分類的方式建構預測模型。例如一篇文章丟進模型演算法,經過拆文解字後,可自動關聯首都跟地名。
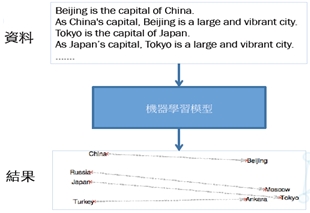
《圖三》
通過觀察來學習做成如何的動作。每個動作都會對環境有所影響,學習物件根據觀察到的周圍環境的反饋來做出判斷。像是打電動一樣,經由經驗來解決每一次的難關。

《圖四》
對應不同的學習型態,有不同的機器學習演算法,主要列出幾種常見的演算法:
一、迴歸分析Regression:
利用變數之間的關係建立迴歸模型,常見的迴歸演算法有Ordinary Least Squares、Logistic Regression、Linear Regression等
二、聚類方法Clustering Method:
k-means algorithm演算法是一個聚類演算法,把n的物件根據他們的屬性分為k個分割,程式試圖找到資料中自然聚類的中心,並假設物件屬性來自于空間向量,讓目標是使各個群組內部的均方誤差總和最小。
三、決策樹Decision Tree Learning:
建立一個根據資料中實際值決策的模型,用來解決歸納和迴歸問題。常見的演算法有Classification and Regression Tree (CART)、C4.5及Random Forest等
四、貝氏方法Bayesian method:
貝氏模型(Naive Bayes Model)發源於古典數學理論,有著堅實的數學基礎,以及穩定的分類效率。
五、K最近鄰(k-Nearest Neighbor,KNN)分類演算法:
樣本在特徵空間中的k個最相似(即特徵空間中最鄰近)的樣本中的大多數屬於某一個類別,則該樣本也屬於這個類別。
六、聯合規則學習Association Rule Learning:
Apriori algorithm是用來對資料間提取規律的方法,通過這些規律可以發現巨量多維空間資料之間的聯絡,而這些重要的聯絡可以被組織拿來使用。
七、自適應增強演算法Adaptive Boosting:
Adaboost是一種反覆運算演算法,其核心思想是針對同一個訓練集訓練不同的分類器(弱分類器),根據不同的錯誤率給定不同權重,把這些弱分類器集合起來,構成一個更強的最終分類器 (強分類器)。
八、支援向量機Support Vector Machine:
SVM將資料映射到一個更高維的空間裡,在這個空間裡建立有一個間隔超平面,在分開資料的超平面的兩邊建有兩個互相平行的超平面,分隔超平面使兩個平行超平面的距離最大化。假定平行超平面間的距離或差距越大,分類器的總誤差越小。
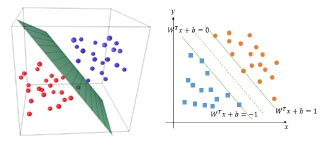
《圖五》
Artificial Neural Networks(人工神經網絡)是一種模仿生物神經網路結構和功能的數學模型或計算模型,用於對函式進行估計或近似,神經網路由大量的人工神經元聯結進行計算。此演算法為非監督式學習的一種,也是開啟深度學習的始祖。
人工智慧因機器學習起了頭,以監督式學習,透過資料特徵及特定標籤,讓機器可以根據給定的特徵去判斷應得的結果,但在大數據時代,許多資料往往沒有這麼完整,無法將每筆資料整理成特定格式,故無法利用監督式學習相關的演算法進行預測分析,只能選擇需要較多硬體資源的非監督式學習相關的演算法進行分析,像是類神經網路演算法。
類神經網路過去因為電腦計算能力的不足,卻又需耗費龐大的計算能力,以及只有一層隱藏層時效果不如Logistic Regression等傳統統計方法,多層隱藏層時又因當時電腦計算能力的不足而導致效能不佳,以致80年代後期,類神經網路演算法的研究就進入大寒冬,連各家期刊都把類神經網路演算法打入冷宮,只要有類神經字眼的論文一律視為垃圾不刊登。但在2006年,Hinton等人提出新的類神經觀點,但為了不讓黃金變垃圾,所以他們用了另一種字眼來詮釋類神經網路,也就是「深度學習」,而他們那年發表了「A fast learning algorithm for deep belief nets」這篇論文,讓類神經網路就此復甦,再加上摩爾定律的效應與分散式架構的興起,現今的硬體運算能力已足夠讓深度學習有更蓬勃的發展。
深度學習 - 使人工智慧讓世人震驚
電影《鋼鐵人》中的Jarvis是大家熟悉的人工智慧電腦兼虛擬管家,此技術是人工智慧嚮往的藍圖,稱之為廣義的人工智慧。深度學習是人工智慧的一個分支,為狹義的人工智慧,其演算法就是機器學習中類神經網路(Neural Network)的延伸。2012年,Hinton的兩位學生,別於過去使用CPU耗時的計算,利用負責處理圖形的GUP搭配深度學習技術,在每年史丹佛大學都會舉辦ImageNet圖像識別競賽中,以超低的錯誤率取得冠軍,一戰成名,學術界開始瘋狂討論,並積極的想應用在各個領域。不過簡單來說,深度學習就是大量的訓練樣本、龐大的計算能力和靈巧的神經網路結構設計而成。
《圖六》
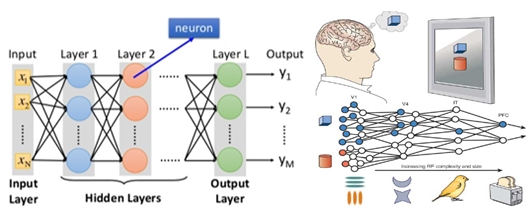
類神經網路演算法,即仿造人腦的運作方式讓電腦進行計算,以多節點及分層的概念擷取資料特徵進行建模,結構上分為三部分:
一、輸入層(Input layer):
多個神經元(Neuron)接受大量的非線性資料訊息,稱為輸入向量。
二、輸出層(Output layer):
訊息在神經元鏈接中傳輸分析而產生結果,稱為輸出向量。
三、隱藏層(Hidden layer):
是輸入層和輸出層之間眾多神經元和鏈接組成的各個層面。隱藏層可以有多層,節點(神經元)數目不定,習慣上會用一層,數目越多則非線性越顯著,但計算時間較多。
《圖七》
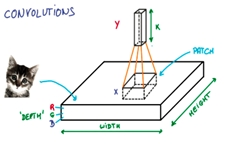
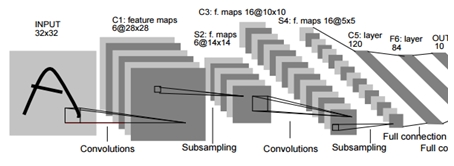
深度學習的演算法係由類神經網路延伸,包含深度神經網路(Deep Neural Networks, DNN)、卷積神經網絡(Convolutional Neural Network, CNN)、深度置信網路(deep belief networks,DBN)、時間遞歸神經網絡(recurrent neural network)、結構遞歸神經網絡(recursive neural network)等,其中CNN是最常見的深度學習架構之一,因為網路架構中的卷積層(Convolutional layer)及池化層(Pooling layer)強化了模式辨識(Pattern recognition)及相鄰資料間的關係,使卷積神經網路應用在影像、聲音等訊號類型的資料型態能得到很好的效果。
卷積層通常由多個濾波器組成,每個濾波器會對不同的影像模式(Image pattern)進行加權,這些動作也是由訓練過程做出來的,所以卷積層可以針對不同的問題產生出不同效果。池化層是將訊號降低維度。一般用於影像識別的卷積神經網路,會在處理輸入資料時,有一到三次的卷積層加池化層的處理,之後再接全連接層(Fully connected layer),才輸出預測結果。舉例來說,一張圖片丟進模型建模判斷,會將圖片拆成許多小方格,根據每個方格的長寬高(顏色)進行模型比對,判斷在多少百分比的信心水準下,該圖片屬於什麼。
《圖八》
《圖九》
在深度學習及硬體技術的發展下,漸漸勾勒出人們想像的人工智慧,雖然離科幻電影中想像的人工智慧仍有很大的差距,但目前人工智慧的技術,包含像圖片、人臉、聲音辨識還有商業決策、生技醫療或是智慧生活,甚至是打敗人類的AlphaGo等,有如寒武紀的生物大爆發,經歷多次演化才成為今日的樣貌。深度學習讓許多科技公司或是科學家不斷的挖掘他的潛在能力,如何充分應用深度學習在各個領域,仍是各界研究的重點,也是非常大的挑戰,期待往後充滿人工智慧的世界。