淺談聯合型用戶需量競價之用電預測技術
作者/李凱平
前言
全台夏季用電負載屢創新高,需量反應是作為彌補電供電不足之一方法,為參與台電公布之需量競價措施,電力負載預測是投標之重點依據。透過機器學習中支援向量回歸(SVR,Support Vector Regression)演算法,以歷史用電量及溫度等資訊作為輸入特徵參數,建立用電需量之預測模型,再經由模型預測計算出各個客戶可卸負載量,提供代表戶能在進行電力調度前進行評估,並決策出各個客戶需要抑低的用電量,以達到減少電費支出的目的。
機器學習–SVR演算法
一、SVM方法原理
在機器學習及資料探勘中,支持向量機(Support Vector Machine, SVM)是經常被應用的監督式學習方法,可用來處理分類或迴歸問題。將SVM用於迴歸分析則稱為是支持向量迴歸(Support Vector Regression,SVR),可解決許多資料非線性問題。因電力需量會因時間與季節的變化而有時序變動,目前已經有很多的電力負載預測是利用SVR演算法,如(Chen et al., 2004)以SVR進行電力負載預測等。
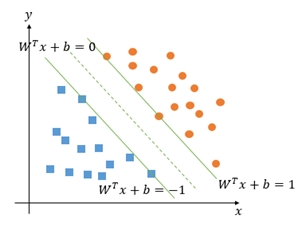
《圖一》SVM示意圖
SVM主要的概念,是希望可以在一個不同類別混合的資料集中,根據不同的特徵,找到一個最佳的區分超平面(separating hyperplane)將不同類別的資料分開來。右圖所示,所謂最佳區分超平面就是其距離兩個類別的邊界可以達到最大,為尋求最大邊界,此類型資料須滿足下列兩限制式:

合併(1)、(2)可得下列不等式:

可由(1)、(2)求得兩平面之間的距離為
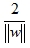
,其中
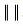
為2-norm,因此欲求得具有最大邊界的區分超平面,可在滿足限制不等式(3)的條件下,求
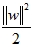
的最小值,利用Lagrange法求解,方程式如下:
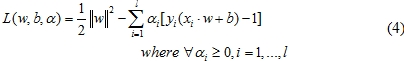
針對式(4)中w及b偏微等於0求極值代回推導,再經由Fletcher(1987)所提出的Karush-Kuhn-Tucker (KKT) complementarity conditions,可得最佳分類問題的函數如下:
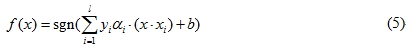
當f(x)>0時,表示該資料與標記為1的資料屬於同一邊,反之當f(x)<0則表示該資料與標記為-1的資料屬同一邊。
二、核心函數
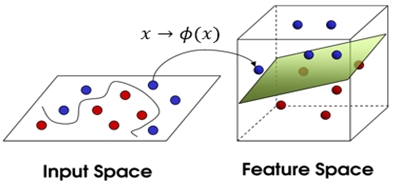
《圖二》資料空間轉換至高維度特徵空間示意圖
核心函數(Kernel function)是將資料在原始輸入空間映射到較高為度的特徵空間(Feature Space)的一個轉換函數,使得原本無法以線性分割的樣本能在新的特徵空間利用一線性函數或是一超平面函數分割如圖二,其中
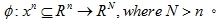
經推導後,可得最佳分離超平面方程式為:
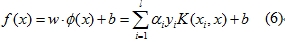
核心函數的形式不斷被學者拿出討論,下表為常用幾個常用的核心函數。

《表一》常用核心函數參考
若原始資料無法以線性函數建立模型時,為尋求非線性映射,需引用上述核心函數轉換到較高維度的特徵空間,如圖三所示,通常選擇
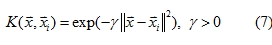
《圖三》SVR非線性轉換示意圖
則在此特徵空間之最佳線性分割函數為
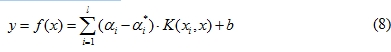
利用台灣大學林智仁(Chih-Jen Lin)博士等開發設計的LIBSVM,進行建築物電力耗能建模預測。將智慧電表的數據,依照給定之資料格式(圖四),其中格式定義為「
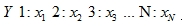
」,輸入進行訓練後找出模型最佳特徵參數,以預測隔日24小時之用電需量
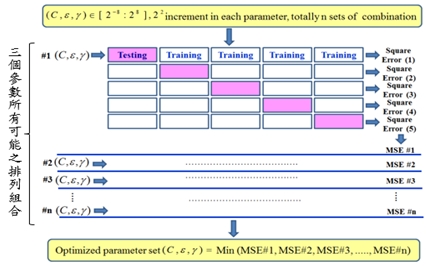
《圖四》SVR模型之最佳化參數找尋
要建立一個優良的預測模型,要藉由適當的特徵參數參與建模,以計算出表現最佳的模型參數。本文應用的電力資料與時間及溫度有極強的關聯性,而由於假日與非假日的耗能模式差異頗大,故在資料篩選方面,先將假日與非假日區別開來(如圖五),然後個別建立每15分鐘的SVR模型,故共有96個非假日SVR模型以及96個假日SVR模型(共192個)。在資料輸入部分,非假日將以「當前這一小時之耗電量」為預測目標,而以「前24、48、72、96、120小時時段之耗電量」為特徵參數;假日部分同樣以「當前這一小時之耗電量」為預測目標,而以「前兩周末六日同一個小時時段及前一小時時段之耗電量」為特徵參數。為避免模型過度配適,本文將使用交互驗證的方式來避免,亦即將訓練資料分成多個子集合,分別對模型作訓練參數修正。
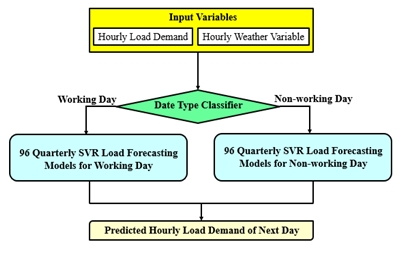
《圖五》SVR電力負載預測模型
在統計上,於資料分析與建模的過程中,遺漏值是一個非常重要的議題。例如在本文中所應用的電力系統案例當中,可能因電表設備運作狀況不穩、網路品質、建築物營運狀況及氣候等因素,導致讀表資料遺漏。為維持資料的完整性,在不捨棄遺漏值建模的情況下,本文利用「同時段區間需量比例差補法」進行補值,由下圖可發現,原始資料因為缺值導致電力需量資料有凸波震盪的現象,補值後,結果與同時段相比,接有相同趨勢,故此補值法在此情況是堪用的。
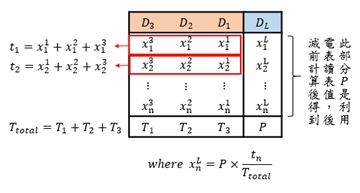
《圖六》同時段區間需量比例差補法
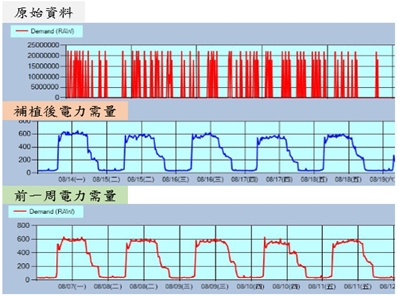
《圖七》補值結果對照圖
本文以某商業辦公大樓以及某橡膠工廠為例,圖形中紅色代表實際需量,藍色代表預測需量,棕色為基準用電容量,綠色為抑低區間需量。
在商業辦公大樓的部分(如圖八),可發現實際電力需量在上班時段增高是合理的,而預測需量線也與實際用量呈現相同趨勢;在橡膠大樓的部分,實際需量也符合工廠種午休息作業的情形,預測需量線也算貼近實際需量。最後可利用預測值與實際值進行差異驗證,以平均絕對值誤差率(Mean Absolute Percentage Error, MAPE)來進行耗能預測誤差驗證,MAPE公式如下:
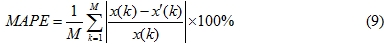
其中當MAPE(%)小於10%是屬於高準確預測,介於10% ~ 20%之間是優良預測,介於20% ~ 50%之間是合理預測,大於50%則是不準確預測。經驗證後發現可得知每日實際值與預測值的誤差率皆小於15%以內,可以驗證此用電需量預測是屬於優良的。
在卸載部分,以模擬方式進行卸載,根據不同場域給定的可卸載設備容量進行抑低,模擬時間為兩小時,再以假設之契約容量,進行效益評估,計算可減免電費,並顯示至畫面首頁供用戶參考。
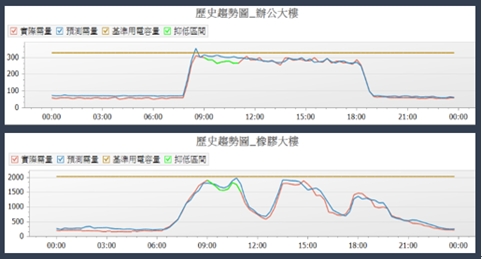
《圖八》補值結果對照圖
實際需量與預測需量歷史趨勢圖
結論
本文利用機器學習SVR演算法建構電力需量預測模型,並透過智慧電錶收集許多場域進行未來24小時之電力負載預測,根據預測結果,可提供用戶在參與台電之需量競價措施中進行抑低的參考。
根據研究發現,部分場域因特定產業特性,導致作業時間沒有規律性,例如某工廠會因偶有大量訂單而頻用電不規律,故本文之預測方式在此場域並不適用。
最後因目前於研發階段,尚未與廠商協議能否配合卸載,故僅利用模擬方式進行效益評估,希望未來能有機會能實際應用在參與台電需量競價措施的用戶中,協助用戶節能且獲益。
參考文獻
1.
台灣電力公司, 什麼是「需量反應」?
2.
台灣電力公司, 需量競價措施
3.陳束弘,2014,「電力耗能負載預測與節能應用」,台灣能源期刊,第一卷,第五期,第601-612。
4.B. J. Chen, M. W. Chang, and C. J. Lin, 2004.Load Forecasting Using Support VectorMachines: A Study on EUNITE Competition2001, IEEE Trans on Power Systems, Vol. 19,No. 4, pp. 1821-1832.