漫步在雲端-分散式系統實作
作者/蔡碧展
前言
隨著網際網路的興盛與分散式系統的盛行,越來越多人將檔案廣泛分散在網路之間,管理者在嘗試保持使用者連線存取他們所需的資料時,也面臨日益擴大的問題,再加上網路本身就是不可靠的,因此如何用一個安全且有效率的方式來完成所需的系統功能,就顯得更為迫切。
以線上文件儲存的服務而言,大致可分為兩個群體,一為使用者,二為服務體供者,對使用者而言,首要考慮的是方便性以及安全性,除了要能讓用戶上傳自己的文件或檔案,使其可隨時隨地在任一電腦透過網際網路存取使用;應該還要可以防止文件被竄改、或是被駭客竊取,使用戶的資料與隱私具有一定的安全性;此外,若伺服器有任一節點失效時,也應能持續的提供完善的服務。對服務提供者而言,系統的設計應該要能容易擴充,以便在使用者與使用者資料在越來越多的情形下,能盡可能的降低擴充伺服器的時間與成本。
為解決上述各需求本文提出一個能提供完善且良好服務的系統,並將在系統設計與實作過程中所遇之瓶頸在本文提出討論。
架構概述
「分散式運算」是將一個繁瑣的大型任務切割成各個小任務後,分別交給多台電腦各自進行運算,運算完後再彙整其結果以完成單一電腦無法勝任的工作或提高整體工作效率。
本文希望能在不安全的網際網路中實作一個分散式系統,且此系統能供用戶上傳檔案,並可對這些檔案做檔案處理的動作,然而這是具有一定難度的,在複雜的網路環境中設計一個分散式系統所會遇到的問題相當複雜,例如各節點之間的溝通與同步化、任務的分配或當系統中某個節點失效時,必須能將該節點未處理的工作分配給其他節點的系統容錯等問題,此外還要考慮到當使用者人數越來越多的情況下,系統是否能容易擴充以滿足越來越龐大的資訊量。
在下列各主題中,我們將上述所提之問題轉化成為本系統所應具備之功能,並做簡單敘述與介紹。
Client與Server間的訊息傳遞方式
對一個提供服務的分散式系統而言,如何將需求分配給系統中的各節點處理是相當重要的一環,在JobTracker與TaskTracker的訊息傳遞部分,本系統採用的是同步式I/O與非同步式I/O,下列本文將針對同步式I/O與非同步式I/O各舉一例說明。
以同步式I/O而言,當TaskTracker發送請求給JobTracker後,會等候JobTracker的回應,當TaskTracker收到JobTracker的回應後,才會繼續下一步動作。下圖為TaskTracker發送其缺少執行任務所需的檔案時,發送索取檔案的請求給JobTracker的情形。如圖1所示,TaskTracker發出請求後,便等候JobTracker的回應,當JobTracker回應其所要求的檔案後,才會進行下一步動作。
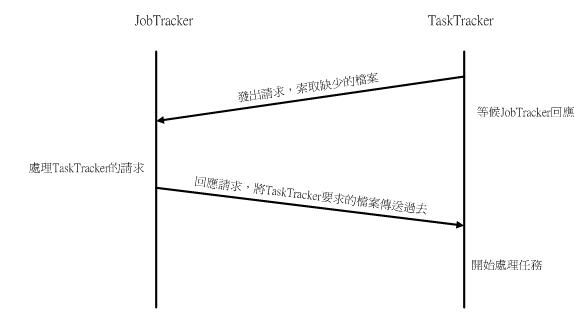
《圖一》同步式I/O
以非同步式I/O而言,當TaskTracker發出訊息給JobTracker後,不必等候JobTracker的回應,就會繼續下一步動作。下圖為TaskTracker發送訊息給JobTracker的情形。如圖2所示,TaskTracker發出請求後,不需等候JobTracker的回應,直接繼續完成自己的任務。
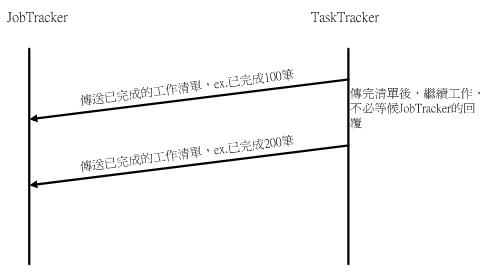
《圖二》非同步式I/O
在本系統中,處理User任務的處理單元會依據其本身硬體處理器的核心數建立多個處理任務的執行緒來共用一份工作清單,以充分利用該處理單元的硬體資源,為達此目的就須考量同步化的問題,避免對系統產生不利影響。
針對此一問題的作法為當所有的TaskThread共用一份清單且要進入清單內讀取欲處理的檔案資訊時,每次的讀取只能有一個TaskThread能進入此清單內讀取資料,而當有一TaskThread在讀取資料時,其餘的TaskThread必須在外面等候裡面的TaskThread讀取完資料離開清單後,才能進入讀取,請注意當清單內的檔案資訊被讀取過後,該筆檔案資訊會從清單內移除,以避免多個TaskThread讀取同一筆檔案資訊。
任務分配
正如上述所言,分散式運算是將一個繁瑣的大型任務切割成各個小任務後,分別交給多台電腦各自進行運算,因此如何切割任務並分配任務,使系統中的各處理單元能負載平衡,維持系統效能就顯得重要。
本系統針對任務的處理是採用先到先處理(FIFO)的方式,也就是利用JobQueue來儲存任務的執行順序,依照使用者送出任務的先後時間依序交由JobTracker作任務分配,且必須滿足一個任務已全部完成的條件,才會再處理第二個任務。
而主要負責處理任務的有4個處理單元,因此JobTracker會將客戶端的所要處理的檔案數平均分配,也就是說如果客戶端欲處理的檔案數為100個,那麼每個處理單元分配到的個數為25個。然而,我們要考慮的檔案的儲存問題,因為不是每個處理單元都擁有其所要處理的檔案,因此本系統會辨別各個處理單元所擁有的檔案,然後依據其擁有的檔案平均分配任務給各處理單元,以避免某處理單元沒有任務中要其處理的檔案,還要去跟其他擁有該檔案的處理單元索取的情況。
然而,有許多的因素會影響處理單元的處理速度,例如,硬體設備、處理的檔案大小等,當某個處理單元已經處理完其本身的任務後,該空閒的處理單元會向JobTracker詢問是否有處理單元尚未處理完,若有處理單元仍在處理檔案,則JobTracker會將未處理完的任務再平均分配給空閒的處理單元,以提高系統執行速度。
系統容錯
分散式系統中,節點的運作是否正常是很重要的一點,倘若節點失效而系統又無容錯機制,則會導致系統的嚴重錯誤。以下將針對處理任務時節點失效的情境來介紹。
分散式系統中擁有著許多的處理單元在處理工作,而在現實環境中,有太多的因素可能會導致處理單元的失效,當處理單元正在執行任務時,可能因為網路問題、電源問題等而導致其無法繼續運作,此時,就必須將此處理單元尚未處理完的工作交由其他處理單元來作處理。
本系統是經由回報進度的方式來監控各處理單元的處理情形,假設某處理單元已處理完N筆資料(本系統預設為處理100筆回報一次),則會傳送訊息告知JobTracker其已完成N筆資料,本系統是利用HeartBeat的方式來監控處理單元是否仍在運作,方式為處理單元每隔一定時間會傳送一個HeartBeat給JobTracker(本系統預設為5秒),若處理單元超過10分鐘未送HeartBeat則視該處理單元已經失效,那麼JobTracker會根據該處理單元先前的進度回報將剩餘未完成的工作平均分配給其他處理單元,而若失效的處理單元已恢復運行,則JobTracker會重新分配新的任務給該處理單元,以維持系統的效能。
Heart Service
此HeartBeat Service主要延續上一小截所提HeartBeat來詳細介紹,其目的為使master能夠掌握slaves的狀態(是否仍在線上),以便工作分配予處理能更有效的被執行。過程中主要會用到的ConnectionEvent:clientOnline(), clientOffline(), synIncoming() 以及ClientConnectionEvent:serverOffline(),其詳細說明如下:
- 系統啟動後,slave會發送SYN1和synIncoming (也就是發送Host,Host記錄了slave的相關資訊,ex:CPU使用率)到master。
- master收到SYN1時,會檢查Client List中是否有此slave的IP,若無此IP則呼叫clientOnline,將此IP加入clientList,並傳回ACK1給salve。
- 利用一SlaveCheckThread來檢查slave是否仍在線上,方法為預設每30秒檢查一次是否收到clientList中的slave發送的SYN,若超過30秒未收到,則呼叫clientOffline將此slave中clientList中移除。
- slave端若送預設的20次(若第一次無法連線,而後每1秒連線1次,直至20次)SYN後仍未收到master回傳的ACK,則呼叫serverOffline,用以表示slace無法跟master連線。
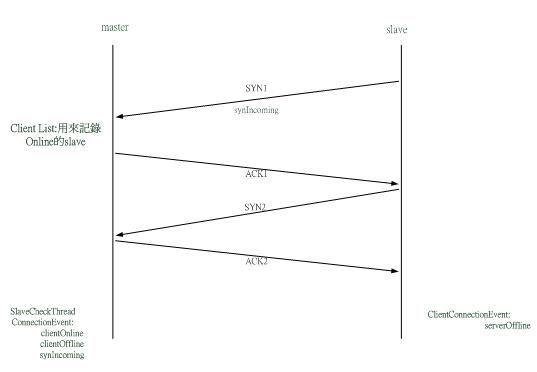
《圖三》HeartBeat Service
本系統由NameNode以及DataNode所組成,圖4。 NameNode負責接收外來指令以及分配工作,DataNode則只負責執行接收到的命令(命令可以來自任何地方)。DataNode告知 NameNode上線後,開始等待接收並執行命令。Message負責NameNode以及DataNode之間的溝通,帶有該執行的指令(Command)以及需要的Argument。本系統複本策略採用RR循環方式(ex. 副本=2 DN=5 ,當檔案送給本系統,檔案會以12,34,51,23….循環存放)。
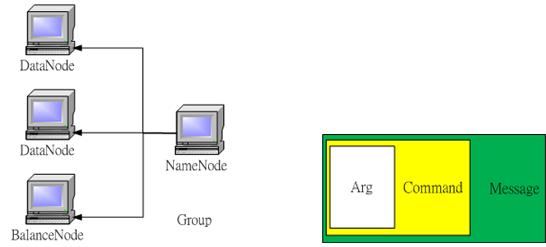
《圖四》DFS架構圖
一般而言,分散式系統在越多台DataNode的情況下效能會越好,在考慮DataNode數量眾多的情況下,系統的可擴性相當重要。對管理者來說,每新增一台DataNode若要耗費許多時間,累積起來的時間耗費十分可觀。本系統考慮到此情況,故新增DataNode時,只需在欲新增的電腦主機上執行本系統指定的程式,即會自動列入本系統的DataNode清單中之後由NameNode收集,減輕管理者新增節點的負擔。
而新增DataNode除了要降低新增的時間外,在工作的分配上也需要納入考慮,若系統偵測到有新增的DataNode加入,理應也將處理的工作分配給此DataNode,如此一來才不至於有DataNode處於閒置狀態。本系統的做法是將系統中原有的各DataNode中的未處理任務進行重新分配,使得新進的DataNode也能即時的分擔工作的處理,達到立即新增立即加入工作,提升整理處理效率。
備援機制
目前進度是當第二台以上的NameNode會去複製先前已啟動NameNode上的fsImage和editLog檔案,只要NameNode檔案一有更新就會傳送給其他的NameNode(balanceNode)做訊息紀錄等作業,但由於目前程式架構的模式NameNode設計成無法被結束或是結束後系統也跟著結束,因此無法算是完整功能。
系統流程
在系統啟始時,各節點會先啟動server以判斷型態為DataNode or NameNode,如果該節點是DataNode則會與NameNode建立連線,並等待JobTracker分配工作。
圖五為本系統執行時的一般流程,也就是客戶端將檔案或資料傳送到Server,Server接收檔案後會進行分散式儲存檔案的動作,爾後用戶傳送所要處理的任務給Server,Server將任務切割成多個小任務後,分配給系統中的節點處理,並將處理完的結果彙整後回傳給用戶的情形。
下列敘述為各步驟的詳細解說:
1.1.Server必須先啟動,使User及其他DataNode能與Server溝通。
1.2.Server啟動後,DataNode會連線到Server的NameNode,等候Server之後的指令。
1.3.User傳送檔案至Server的本機系統。
1.4.NameNode從本機系統取得檔案後,將檔案發送至DataNode儲存,每一份檔案在本系統預設為儲存3份,請注意,檔案在DataNode儲存後,NameNode只保留關於檔案的相關資訊(ex.檔案儲存位置,大小等)。
1.5.User發送檔案處理的任務給JobTracker。
1.6.接收到User的任務後,JobTracker會去向NameNode索取此任務需處理之檔案的檔案清單。
1.7.JobTracker負責將此任務分配給各個TaskTracker去個別處理。
1.8.本系統考慮到現今電腦多為多核心的CPU,故TaskTracker接收到JobTracker所分配的任務後,會將任務丟給TaskThread,再由TaskTracker呼叫模擬器執行檔案處理並建立一個OutputThread等待模擬器執行檔案後的結果,若該處理單元為雙核心則用兩個執行緒處理工作;單核心則用一個執行緒處理工作。
1.9.模擬器處理完一筆檔案資料後,會將結果傳給OutputThread後,再處理下一筆資料。
1.10.檔案處理完的結果會先存在RuncommandList裡,等TaskTracker回報進度給JobTracker時,在同時傳回給NameNode。
1.11.每處理完一定的檔案資料量就會回傳進度給JobTracker(ex. 已完成10筆),此時,RuncommandList也會將已完成的此10筆資料結果傳回NameNode儲存。
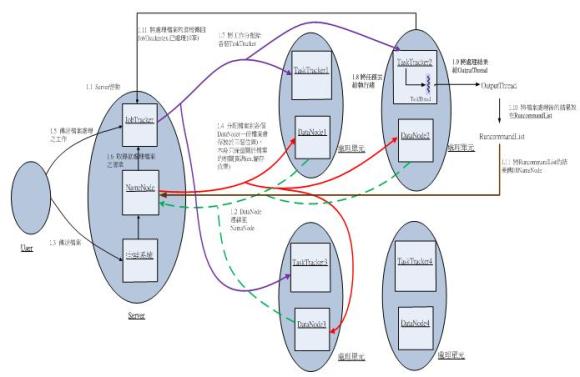
《圖五》系統於正常情況下的執行流程
圖六為當處理任務的TaskTracker中,有某些TaskTracker已完成任務,而某些TaskTracker仍未完成任務時,系統為提升處理效能所採取的措施。
下列敘述為此情形下系統處理的步驟解說:
2.1.TaskTracker每完成10個檔案將會回傳一次任務進度的訊息ex.已完成10個檔案、已完成20個檔案…依此類推,而全部完成時,會回傳任務已完成。以此情況而言,TaskTracker1已完成JobTracker所分配的工作,而此時,TaskTracker3只完成50%(50個檔案)。
2.2.當JobTracker收到任務處理的進度回報時,會檢查是否有部分TaskTracker已完成任務,而其他TaskTracker仍有任務未完成,若滿足此條件,則JobTracker會將仍有任務要完成的TaskTracker中的部分任務分配給已完成任務的TaskTracker,以提高系統處理的效率。
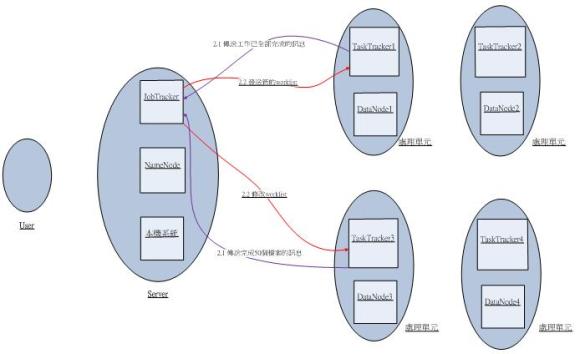
《圖六》修改工作清單的流程
圖七為當系統中有TaskTracker失效時的處理步驟,詳細步驟說明如下述:
3.1.系統中的每個TaskTracker會定時(本系統預設為5秒)傳送訊息給JobTracker,透過此訊息使JobTracker得知哪些TaskTracker正在運作,而當有TaskTracker太久(本系統預設為600秒)沒傳送訊息給JobTracker時,JobTracker會判定該TaskTracker已經失效。
3.2.當JobTracker發現有TaskTracker已經失效時,透過系統的其他機制可以得知該TaskTracker是否有任務尚未處理完,以及尚未處理完的任務清單,此時,JobTracker會將那些尚未處理完的任務分配給仍在運行的TaskTracker,使系統不至於因為某Tasktracker失效而失效。
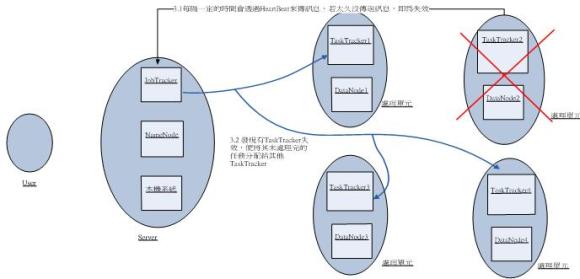
《圖七》當有TaskTracker失效時的流程
本系統除分散式系統本身應具備的基本功能外,也規畫了一些新的功能與機制,以期能減低工作處理時間,提升系統的效能,圖7為JobTracker系統監視畫面。以下將簡述本系統所提供的功能機制:
- 當機器有多個Processor時,就建立多個TaskThread執行緒來執行任務。
- 當User送出多個工作時,JobTracker會按照順序依次執行各個工作,也就是先來的工作先執行。
- 在處理任務時,若有節點失效,系統會重新分配任務。
- 當有新節點加入時,會將任務分配給新加入的節點,實現可擴充功能。
- 實作了管理者與使用者介面,透過介面管理者可以得知各個TaskTrcker和本身的系統相關資訊,已達到較好的管理;而使用者可以透過介面上傳檔案至系統中,使用上較為便利與輕鬆。
- 提供mail功能,當NameNode掛掉時,系統可發信通知管理者,使管理者能第一時間得知狀況。
- 擁有備援機制,定期儲存NameNode所擁有的資訊(ex.有哪些TaskTracker、檔案儲存在哪些DataNode等)。故當原有的NameNode掛掉時,可將儲存的資訊複製到新決定的NameNode,新決定的NameNode是從各個DataNode中自動挑選。
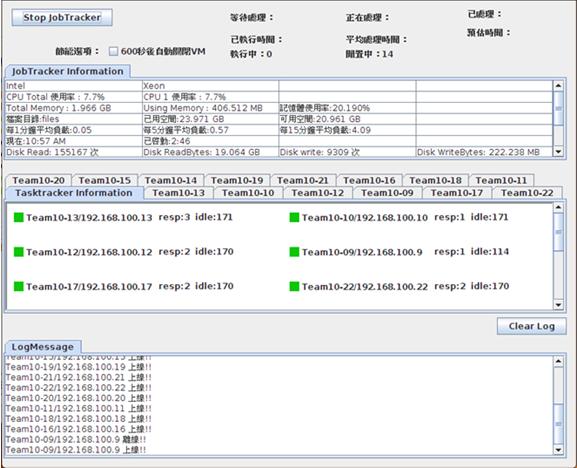
《圖八》JobTracker系統監視畫面
1.Dean, J., and Ghemawat, S., 2008, “MapReduce: Simplified Data Processing on Large Clusters”, Communications of the ACM, 51(1): p. 107-113.
2.Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E. Gruber, 2006, “Bigtable: A Distributed Storage System for Structured Data”, 7th USENIX Symposium on Operating Systems Design and Implementation, pp.205-218.
3.Hadoop, http://hadoop.apache.org/.
4.Nutch, http://nutch.apache.org/.
5.Sanjay, Hgobioff, and Shuntak, 2003, “The Google File System”, 19th ACM Symposium on Operating Systems Principles(SOSP).
6.Scaling Hadoop to 4000 nodes at Yahoo!, http://developer.yahoo.net/blogs/hadoop/2008/09/scaling_hadoop_to_4000_nodes_a.html.
7.Welcome to NCHC Cloud Computing Research Group, http://trac.nchc.org.tw/cloud.